
[Abstract]
불균형 데이터 분포는 데이터가 일반적으로 긴 꼬리 분포를 나타내는 산업에서 머신 러닝(ML) 모델을 구축하는 데 있어 실용적이고 일반적인 과제이다. 예를 들어, 구글 어시스턴트, 아마존 알렉사, 애플 시리와 같은 가상 AI 어시스턴트에서는 재생 음악이나 세트 타이머 발화가 다른 기술보다 훨씬 더 많은 트래픽에 노출된다. 이는 훈련된 모델이 대다수 클래스, 범주 또는 의도에 과적합되어 모델 오보정을 초래할 수 있다. 보정되지 않은 모델은 신뢰할 수 없는(대부분 과신) 예측을 출력하며, 이는 다운스트림 의사 결정 시스템에 영향을 미칠 위험이 높다. 본 연구에서는 온라인 소매점의 고객 서비스 대화에서 제품 반품 이유 코드를 예측하는 실용적인 적용에서 모델의 교정을 연구한다; 반환 이유도 클래스 불균형을 나타냅니다. 훈련된 ML 모델의 결과적인 오보정을 완화하기 위해 초점 손실을 사용하여 모델 개발 및 배치를 간소화한다(Lin et al., 2017). 우리는 표준 교차 엔트로피 손실과 비교하여 더 잘 보정된 모델을 학습하는 데 초점 손실이 있는 모델 훈련의 효과를 경험적으로 보여준다. 보정이 개선되면 훈련된 모델에 대한 정밀 호출 트레이드오프를 더 잘 제어할 수 있다.
[Introduction]
산업에서 ML 모델을 구축하고 개발하는 것은 많은 실질적인 과제가 있다. 불균형 데이터 분포(He and Garcia, 2009), 특히 긴 꼬리 분포(Wang et al., 2021a)는 모델을 다수의 데이터 클래스에 과적합시키고 오보정을 초래한다(Guo et al., 2017; Mukhoti et al., 2020). 즉 모델 예측 확률은 정확성의 가능성을 추정하지 못하고 과확도 또는 과소확도를 제공한다찌그러진 예측. 불균형 데이터를 해결하기 위해 일부 주류 전략은 소수 업샘플링 및/또는 다수 클래스 다운샘플링을 통해 데이터 세트의 균형을 재조정하고 있다.

그림 1: 불균형 데이터 세트 D로 훈련된 ML 모델을 보정하는 절차. 초점 손실을 통해 모델 M은 더 나은 보정 모델 Mc로 학습된다. 후속 단계에서 데이터 세트 Dg는 실제 대화(추론 분포)에서 샘플링되고 황금 데이터 세트로 수동으로 주석이 달렸다. 모델을 추가로 보정하고 정밀도-회수 임계값을 조정하여 특정 정밀도를 달성하거나 고객 요청을 처리하는 데 사용됩니다.
예는 SMOTE(Chawla et al., 2002)를 참조한다.
그러나 불균형 데이터로 인한 오보정은 이러한 방법으로 쉽게 처리할 수 없다. Guo 외 연구진(Guo et al., 2017)은 최근 음성 로그 우도(NLL) 훈련된 심층 신경망(DNN)이 기존 ML 방법에 비해 제대로 보정되지 않는 경향이 있다는 것을 발견했다(Niculescu Mizil and Caruana, 2005a).
불균형 데이터로 훈련된 모델을 교정하는 것은 산업에서 중요한 역할을 한다.
의료 진단(Caruana et al., 2015)과 같은 애플리케이션에서 의사결정은 예측된 클래스뿐만 아니라, 예를 들어 적절한 치료를 결정하기 위해 환자의 위험을 정량화하는 예측 확률에도 의존한다(Caruana et al., 2015). 따라서 예측 확률이 실제 값을 반영하도록 의약품, 재무 관리(Fisher and Krauss, 2018), 자율 주행 자동차(Bojarski et al., 2016)와 같은 고위험 영역에서 모델을 잘 보정하는 것이 특히 중요하다.
본 연구에서는 고객 서비스 챗봇의 반환 이유 코드 예측이라는 실질적인 텍스트 분류 작업을 위한 신뢰할 수 있는 ML 모델을 구축하는 데 있어 초점 손실(Lin 등, 2017)의 효과를 경험적으로 연구한다. 공식적으로, 초점 손실은 다음과 같다:
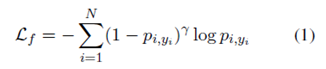
여기서 pi,yi는 i번째 표본의 예측 확률이고 Y는 일반적으로 Y = 1로 설정되는 초 매개변수입니다.
1.1 실무적 고려사항
(1) 이론적 효과. 초점 손실은 원래 산업 데이터에서 자주 관찰되는 불균형 데이터 분포 문제를 처리하기 위해 제안되었다(Kilkki, 2007). 학습 모델에서, 다수 클래스 샘플은 모델이 다수 클래스를 예측하는 데 더 자신감을 갖는 방향으로 가중치를 업데이트하기 위해 최적화 및 경사 하강을 지배한다. 초점 손실은 (Mukhoti et al., 2020)1에 따라 쿨백-라이블러(KL) 발산을 최소화하는 것과 엔트로피를 최대화하는 것 사이의 균형으로 해석될 수 있다:
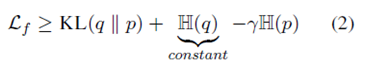
방정식의 근거는 KL 항으로 인해 높은 값(자신감)을 가질 확률 p를 학습하지만 엔트로피 정규화 항으로 인해 너무 높지는 않다(과신감)는 것이다(Pereyra et al., 2017).
(2) 계산 및 알고리즘 복잡성. 온도 스케일링(Platt et al., 1999), 베이지안 방법(Maddox et al., 2019), 레이블 평활(Müler et al., 2019) 및 커널 기반 방법(Kumar et al., 2018)과 같은 많은 인기 있는 교정 방법 중에서 초점 손실은 계산 오버헤드를 증가시키거나 아키텍처 수정을 필요로 하지 않는다. 예를 들어, 널리 사용되는 온도 스케일링(Platt et al., 1999)은 추가 훈련 후 교정이 필요한 반면, 초점 손실은 (eq. (2)를 사용하여) 훈련 내 암시적 교정을 제공한다.
섹션 4에서, 우리는 훈련된 ML 모델을 보정할 때 초점 손실의 흥미로운 특성을 경험적으로 보여줄 것이다. NAT의 기여는 다음과 같이 요약됩니다:
• 우리는 실제 응용 환경에서 모델 오보정을 처리할 때 초점 손실을 사용하는 것의 효과를 경험적으로 조사한다.
• 우리는 분류 임계값을 조정하여 원하는 정밀도 또는 리콜 목표를 달성하기 위해 좋은 보정이 중요하다는 것을 보여준다. 표준 교차 엔트로피 손실은 왜곡된 예측 확률 분포로 인해 이 목표를 달성할 수 없다.
• 우리는 세 가지 대화형 봇 사용 사례에 걸쳐 고객의 요청을 처리하는 챗봇을 통해 보정된 모델의 성능을 입증한다.
[2. Background and Preliminaries]
[2.1 배경]
우리는 ML 모델의 개발 및 배포를 보여주기 위해 온라인 소매점에서 반품 이유 코드의 자동 분류 작업을 고려한다. 고객이 구매한 물품을 반품하도록 요청할 때마다 사유 코드가 결정되어 가장 적절한 해결책을 선택하고 반품을 처리합니다. 예를 들어, 고객이 해당 품목(예: 크기, 색상 또는 재질)에 만족하지 않는 경우 이는 반품 이유인 고객 선호도에 매핑됩니다. 이러한 경우에는 고객이 동일한 문제에 직면할 수 있으므로 동일한 항목으로 대체하는 것은 적절하지 않지만 반품을 처리하고 환불을 발행하는 것이 적절한 해결책이다. 사례 연구에서, 우리는 두 가지 사용 사례, 즉 이진 이유 코드 예측과 다중 클래스 이유 코드 예측을 고려하며, 여기서 우리는 5개의 다른 범주를 고려한다.
[2.2 예선]
본 연구에서는 불균형 데이터 세트로 훈련된 감독 이진 및 다중 클래스 분류기의 교정을 고려한다.
[2.2.1 모델 보정]
교정(Guo et al., 2017)은 예측 확률이 정확도의 실제 가능성을 추정하는 방법을 측정하고 검증한다. 데이터 세트 fx; yg; x 2 X; y 2 Y로 훈련된 모델 m을 가정하자. ^p는 예측된 소프트맥스 확률이다. 만약 m이 각각 신뢰 p = arg max(^p) = 0:9인 100개의 독립적인 예측을 한다면, 이상적으로 보정된 m은 대략 90개의 정확한 예측을 제공한다. 형식적으로, 데이터 세트 D에서 잘못 보정된 경우 정확도(m(D) = 신뢰도(m(D)). 실제로 완벽한 보정을 달성하는 것은 어렵습니다.
[2.2.2 신뢰성 다이어그램]
신뢰도 다이어그램(DeGroot and Fienberg, 1983; Niculescu-Mizil and Caruana, 2005b)은 예측 확률에 따라 예측을 빈으로 그룹화하여 모델이 과신인지 과소신인지 시각화한다. 예측은 N개의 간격 빈(각각의 폭 1=N)으로 그룹화되고 각 빈에서 실측값 레이블 ^yi에 대한 샘플의 정확도는 다음과 같이 계산됩니다:

여기서 = jbnj, 즉 bn 단위의 원소 수. ^pi를 표본 y에 대한 확률이라고 가정하면, 평균 신뢰는 다음과 같이 정의된다
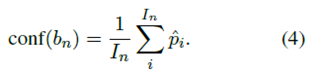
모델은 acc(bn) = conf(bn); 8n이면 완벽하게 보정되며 다이어그램에서 빈은 식별 함수를 따릅니다. 이와 다른 편차는 오보정을 나타냅니다.
[2.2.3 예상 교정 오류(ECE)]
ECE(Neini et al., 2015)는 교정의 스칼라 요약 통계량이다. 모델 정확도와 신뢰도 사이의 차이를 빈에 걸친 가중 평균으로 계산한다.
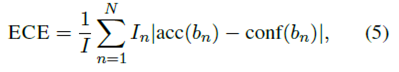
여기서 I는 총 샘플 수입니다.
[2.2.4 최대 보정 오류(MCE)]
MCE(Neini et al., 2015)는 정확도와 신뢰도 사이의 최악의 경우 편차를 측정한다.

신뢰할 수 있는 신뢰성 측정이 절대적으로 필요한 고위험 애플리케이션에서 특히 중요하다. 완벽하게 보정된 분류기의 경우 ECE와 MCE는 모두 0과 같습니다.
[3. 데이터셋 및 구현 세부 정보]
우리는 과거의 인간-고객 서비스 상호 작용에 대한 반환 이유에 대해 기록된 과거 데이터(때로는 시끄럽다)를 사용하고, 배포 전 모델 보정을 위해 인간 주석이 달린 신뢰할 수 있는 데이터를 사용한다.
그림 2: 실험을 위해 무작위로 샘플링된 데이터 세트의 분포는 분명히 불균형한 레이블 분포를 볼 수 있다.

구체적으로, 우리는 이진 이유 코드 모델을 위한 골든 데이터 세트로 1013개의 인간 주석 샘플을 준비했고, 다중 이유 코드 모델을 위한 1839개의 주석 샘플 세트를 준비했다. 섹션 4의 표에 보고된 숫자는 주석이 달린 데이터 세트를 기반으로 한다.
그림 2는 과거 로그에서 무작위로 샘플링된 데이터 세트의 통계를 제공합니다. 온라인 소매점에서 널리 사용되는 반품 사유 4가지를 고려했습니다(자세한 내용은 아래 링크 참조). 이후 "품목에 결함이 있거나 작동하지 않음"(LABEL 0), "부품 또는 부속품 누락"(LABEL 1), "성능 또는 품질이 적절하지 않음"(LABEL 2), "고객 선호도"(LABEL 3). 이진법의 경우, 우리는 하나의 특정 반환 유형 LABEL 0을 탐지하고 다른 반환 이유(기타(LABEL 1))와 구별하는 것을 목표로 한다. 다중 클래스의 경우와 마찬가지로, 우리는 네 가지 광범위한 반환 범주(LABEL 0... 3)를 고려하고 OTHER(LABEL 4) 아래의 다른 모든 반환 유형을 설명합니다. 두 가지 설정 모두 다른 클래스가 가장 자주 사용됩니다. 두 가지 사용 사례 모두에서 레이블 분포가 불균형하다는 것을 알 수 있습니다. 전체 데이터 세트 D의 경우, 우리는 그것을 {Dtrain;}으로 나눈다;열차/발/테스트 분할에 8:1:1의 Dval;Dtest}. 우리는 표준 교차 엔트로피(CE)와 다른 값(FL)으로 초점 손실을 가진 모델을 훈련한다.
우리는 Py-Torch(Paszke et al., 2019)로 모델을 구현했으며, 각 모델은 2개의 양방향 LSTM 레이어와 2개의 밀도 레이어로 구성된다. 내장 치수는 1024입니다. 숨겨진 레이어 차원은 이진 코드 모델과 다중 이유 코드 모델에 대해 각각 128과 512로 설정됩니다. 우리는 임베딩 레이어와 밀집 레이어에 각각 0.1과 0.2의 비율로 드롭아웃을 적용한다. 모델은 최적화 알고리듬으로 Adam(Kingma 및 Ba, 2014)을 사용하여 훈련된다
[4. 모델 선택 및 보정]
이 섹션에서는 85% 정밀도 또는 90% 리콜과 같은 원래 예측 성능을 유지하면서 잘 보정된 모델을 구축하는 방법을 설명한다. 우리는 초점 손실(Lin et al., 2017)을 조정하고 실제 환경에서 이진 및 다중 클래스 텍스트 분류 작업 모두에서 교정 효과(Mukhoti et al., 2020)를 경험적으로 평가한다. 실제로 모델을 사용하는 데 중요한 두 가지 유형의 트레이드오프, 즉 (1) 식별-교정 트레이드오프와 (2) 정밀-호출 트레이드오프를 관찰했다. 우리는 또한 초점 손실에서 Y의 값이 더 잘 보정된 모델을 학습하는 데 중요한 역할을 한다는 것을 발견했다. 우리는 교차 엔트로피로 훈련된 모델을 CE로, 주어진 Y 값에 대해 초점 손실로 FLY로 나타낸다.
[4.1 식별-보정 트레이드오프]
교정 방법은 예측(우리의 경우 차별적) 성능 보존이어야 한다(Zhang et al., 2020).
[4.1.1 이진 이유 코드 예측]
표 1은 서로 다른 손실 함수를 가진 모델의 결과를 보여준다. CE 기반 모델은 최상의 예측 성능을 달성하는 반면 FL 기반 모델은 약간 낮은 점수를 제공한다는 점에 유의한다. 그러나 FL은 교정 관련 메트릭(즉, NLL, ECE 및 MCE) 측면에서 CE보다 훨씬 우수한 성능을 보인다. 또한 Y 값이 높을수록 인간 주석이 달린 샘플에서 교정 성능이 우수하다는 것을 알 수 있다.
그림 3은 예측된 소프트맥스 확률 분포(위)와 신뢰도 도표(아래)를 보여줍니다. (a)-(e)에서, 우리는 확률이 스파이킹 분포(과신: p는 1 또는 0에 가깝습니다)에서 평평한 분포(예: p = f0:6; 0:4g)로 변화한다는 것을 명확하게 알 수 있습니다. 그림 3(f)-(j)는 오보정된 모델이 높은 ECE 및 MCE 점수를 나타낸다는 것을 보여준다. 우리는 또한 신뢰와 정확성의 진정한 가능성 사이의 간격을 통해 이러한 오보정을 관찰할 수 있다. 이 이진 불균형 분류 사례에서, 우리는 교정이 예측 성능을 약간 손상시키지만 겸손하다는 것을 발견했다. 최상의 식별-교정 트레이드오프를 달성하는 후보를 선택하여 최상의 모델을 얻을 수 있다. 여기서 표 1에 따라 FL5여야 합니다.
[4.1.2 다중 이유 코드 예측]
우리는 5가지 이유 코드를 다루는 다중 이유 코드 예측 실험을 추가로 수행했다. 표 2와 그림 4는 잘 보정된 모델을 학습할 때 초점 손실의 효과를 보여준다. 모델의 보정 여부를 측정하려면 골든 데이터 세트로 인간 레이블이 지정된 샘플의 작은 세트를 준비하는 것이 중요하다. 황금 데이터 세트는 우리 모델이 배포 후 예측할 온라인 데이터 분포를 반영한다. 보정 효과의 차이는 그림 4(위 행, (a)-(c))를 비교하여 관찰할 수 있다.
[4.1 Precision-Recall Tradeoff]
모델 정밀도와 리콜 간의 균형(Buckland and Gey, 1994)은 훈련된 모델을 배치하는 데 중요한 측면이다. 예를 들어, 특정 예측 작업에 높은 모델 정밀도(리콜)가 필요한 경우, 리콜(정밀)이 어느 정도 희생되어야 함을 의미한다. 트레이드오프는 분류 임계값 조정을 통해 달성될 수 있다. 이 하위 섹션에서, 우리는 더 나은 보정 모델이 이 목표를 달성하는 데 도움이 될 수 있음을 경험적으로 입증한다.
그림 5는 이진 이유 코드 모델에 대한 정밀도-호출 곡선을 보여준다. 해당 소프트맥스 확률 분포는 그림 3(위)에 나와 있습니다. CE 모델인 그림 5(a)와 그림 3(a)의 경우, 우리는 그것이 더 많은 편광 확률을 제공한다는 것을 발견했다. 즉, 예측 확률이 더 뾰족하다. 이러한 왜곡된 분포를 고려할 때, 주어진 리콜을 기반으로 한 정밀도 또는 예상 정밀도(예: 85%)를 기반으로 한 특정 리콜을 조정하는 것은 어렵다. 반면, 그림 5(b-d)의 FL 모델은 [0;1] 간격에 걸쳐 더 잘 분포되어 특정 정밀도(또는 리콜) 대상에 대한 임계값에 더 적합한 평탄한 확률 분포를 학습한다. 이 동작은 CE 모델과 FL 모델에서 계산된 임계값을 비교할 때 그림 6에서도 관찰할 수 있습니다.
[5. Experimental Results 실험 결과]
고객의 요청을 처리하기 위해, 우리는 세 가지 대화형 사용 사례에 대해 이진 이유 코드 모델을 사용한다3. 이 모델은 고객의 자유 텍스트 입력에 따라 제품 반품이 특수 케이스 LABEL 0인지 여부를 감지합니다. 우리는 예측 이유 코드의 모델 정확도에 대한 내재적 평가와 다운스트림 대화형 챗봇 시스템에 대한 외적 평가를 모두 통해 모델의 성능을 분석한다. 배치하기 전에, 우리는 LABEL 0에 대한 임계값= 0.185로 예상되는 85% 정밀도를 달성하도록 모델을 조정했다.
그림 3: 빈이 10개인 이진 이유 코드 모델에 대한 신뢰성 다이어그램 그림. 대각선 대시 라인은 완벽한 보정을 제공합니다(특정 빈에서 신뢰도는 정확도와 동일합니다).
표 1: 1013개의 인간 주석이 달린 샘플에서 CE와 초점 손실(다른 값)을 가진 이진 이유 코드 모델의 성능. 예측 성능(예: 정확도)의 경우 모델 간의 차이는 무시할 수 있다. 그러나 교정 관련 메트릭(하단 행)에서 FL 기반 모델은 훨씬 더 나은 성능을 보여준다. 표 2와 같이 최고 점수는 굵은 글씨로 표시하고 두 번째 최고 점수에는 밑줄을 그습니다
표 2: CE 및 초점 손실(값이 다른)이 있는 다중 사유 코드 모델의 성능.
[5.1 본질적 평가]
우리는 모델이 제공한 실제 대화의 접촉 샘플에 대한 모델의 예측에 대한 인간 평가를 수행한다. 먼저, 우리는 이유 코드 모델이 LABEL 0 코드를 예측한 485개의 접점을 무작위로 샘플링한다. 이러한 접점에 수동으로 주석을 달아서 384=485가 올바르게 예측된다는 것을 발견했다. 즉, 모델은 배포 후 83:8%의 정밀도를 달성한다. 이는 오프라인 테스트 세트에서 계산된 정밀도(81:4%)와 잘 일치합니다.
우리는 주로 정밀 메트릭에 관심이 있지만, 향후 개선의 기회 분석을 위해 모델의 음의 예측 값도 분석한다. 우리는 모델이 LABEL 0 코드를 예측하지 않은 200개의 접점을 무작위로 샘플링했다. 200개의 접촉 중 194개의 예측이 사실이라는 것을 발견했다. 즉, 모델은 194=200=97%의 높은 정밀도를 다른 사람들에게 보여준다.
그림 4: 빈이 10개인 다중 이유 코드 모형에 대한 신뢰도 도표 그림. 대각선 대시 라인은 완벽한 보정을 제공합니다(특정 빈에서 신뢰도는 정확도와 동일합니다)
[5.2 외부 평가]
다운스트림 애플리케이션에서 우리 모델의 영향을 평가하기 위해, 우리는 세 가지 사용 사례에서 대화형 봇에 대해 제시된 모델이 있든 없든 온라인 A/B 실험을 실행한다. (1) 제어 분기: 고객이 선택한 이유 코드가 있는 대화형 봇; (2) 처리 분기: 반환 이유 코드에 대한 추가 확인이 있는 대화형 봇(LABEL 0)) 고객 무료 텍스트 입력.
대화형 봇을 평가하기 위해 (1) 자동화 속도(AR): 인간의 개입 없이 대화형 봇에 의해 해결된 연락처의 %, (2) 양성 반응 속도(PRR): 고객이 챗봇이 제공한 해상도에 긍정적으로 응답한 횟수의 %, (3) R을 측정한다반복 속도(24RR): 고객이 24시간 안에 같은 이슈에 대해 다시 연락하는 비율입니다.
표 3은 2주 동안의 이러한 주요 측정 기준에 대한 결과를 보여줍니다. 결과에서 관찰할 수 있듯이, 이유 코드 모델은 자동화 속도 및 고객 경험 관련 메트릭 모두에서 대화 시스템의 성능을 향상시킨다. 이는 봇이 특정 고객 상황에 따라 적절한 솔루션을 제공할 수 있도록 함으로써 달성됩니다.
표 3: 세 가지 애플리케이션(위, 중간, 아래)에 대한 모델의 온라인 평가. 상대적인 숫자가 보고됩니다. AR과 PPR은 높을수록 좋고 24RR은 낮을수록 좋다. 기밀 문제로 인해 성능 관련 수치만 보고합니다. C: 제어 분기; T: 치료 분기.
[6. Related Work]
Guo et al.(Guo et al., 2017)과 Mukhoti et al.(Mukhoti et al., 2020)은 더 크고 현대적인 네트워크의 오보정이 훈련 데이터 세트의 가능성에 대한 과적합과 관련이 있음을 보여주었다. 기존의 NN은 정확도가 이미 완벽하더라도 긍정적일 수 있는 부정 로그 우도(NLL)를 최소화하도록 훈련된다. 현대의 네트워크는 정확도가 최적화된 후에도 훈련 중 NLL을 계속 최소화하여 훈련 데이터 세트에 과적합하고 결과적으로 잘못된 예측에 점점 더 자신감을 갖게 된다. 이를 해결하기 위해 연구자들은 초점 손실(Lin et al., 2017), 최대 엔트로피 정규화기 역할(Mukhoti et al., 2020), 온도 스케일링(Guo et al., 2017)을 포함한 모델 예측 확률에 대한 다양한 정규화기를 제안한다. Muller et al. (Müller et al., 2019)은 라벨 평활을 사용하여 네트워크 출력을 정규화할 것을 제안한다. 또한, 베이지안 방법(Maddox et al., 2019), 메타 학습(Bohdal et al., 2021), Gumbel-softmax Trick(Jang et al., 2017; Wang et al., 2021b) 및 커널 기반 방법(Kumar et al., 2018)과 같은 최근의 몇 가지 방법이 훈련에서 직접 더 나은 보정 모델을 학습하기 위해 제안되었다.
[7. 논의]
실제 시나리오에서 모델을 보정할 때, 보정의 복잡성은 고려해야 할 문제이다. 초점 손실(Lin et al., 2017; Mukhoti et al., 2020)은 엔트로피 정규화를 통해 훈련 중 교정을 제공한다(Pereyra et al., 2017). 이 작업에서 우리는 훈련된 ML 모델을 보정하는 간단하고 효과적인 방법을 제공한다는 것을 분석적으로 보여주었다(섹션 4). 한편, 경우에 따라 데이터 세트의 가치를 조정해야 합니다. 실험적으로, 우리는 높은 값을 설정하는 것이 좋은 교정 성능을 제공하면서 예측 성능을 크게 해치지 않는다는 것을 발견했다.
그림 5: 이진 이유 코드 모델에 대한 정밀도-회호 곡선. (a) CE 모델은 더 많은 편광 확률을 제공하고 주어진 회수를 기반으로 정밀도를 조정하는 것을 어렵게 한다. (b-d) FL은 더 나은 분산 확률, 정밀도 또는 리콜을 더 쉽게 조정할 수 있도록 학습한다.
그림 6: 이진 이유 코드 모델의 임계값에 대한 정밀도 및 리콜 곡선.
[8. 결론]
본 논문에서, 우리는 더 나은 보정 모델을 학습하는 데 초점 손실을 사용하고 심층 신경망 모델의 실제 적용에서 정밀 호출 트레이드오프를 찾는 효과를 경험적으로 보여주었다. 우리는 불균형 데이터 분포로 인한 오보정과 교차 엔트로피 훈련 모델을 실제 환경에서 사용하는 기존 문제에 대한 심층 분석을 수행했다. 우리는 또한 이론적으로 엔트로피 정규화 항을 제어하는 하이퍼 파라미터가 모델 보정에 중요하다는 것을 보여주었다. 우리는 실제 사용 사례에서 ML 모델의 배포를 연구했고 더 나은 보정이 사후 임계값을 통해 정밀 호출 트레이드오프를 제어하고 배포 후 메트릭을 개선하는 데 도움이 된다는 것을 입증했다(온라인 A/B 테스트에서).
윤리적 고려사항 개발 및 실험. 우리는 모델을 훈련시키기 위해 익명화된 텍스트 대화 스니펫을 사용했다.이 작업에서 설명한 특정 모델은 고객 정보를 노출할 수 있는 방법이 없습니다. 우리는 실험에 사용된 데이터 세트를 공개하지 않는다. 고장 모드. 시스템 오류와 관련된 위험과 관련하여, 본 연구에서 설명한 모델에 대한 잘못된 예측은 잘못된 반환 이유 할당을 초래할 수 있습니다. 그러나 챗봇과 상호 작용하는 고객은 시스템이 예상대로 작동하지 않는다고 판단할 경우 인간 동료와 대화할 수 있는 옵션이 있기 때문에 이러한 잘못된 분류와 관련된 실제 위험은 제한적이다.