
Extracting document-level relationships using the integrated model of SSAN and JEREX
하찮은 제 KSC2022 논문입니다.. 허허
요 약
관계 추출은 문장 내의 두 개체 간의 관계를 분류하는 태스크이다. 기존 파이프라인 방식의 관계 추출 모델은 개체명 인식 단계에서 관계 분류 단계의 정보를 사용할 수 없다는 문제가 있으며, 기존 문장 수준 관계 추출은 한 문장에 같이 등장한 두 개체에 대해서만 관계를 추출할 수 있다는 문제가 있다. 위해서, 최근 관계 추출 연구는 개체명 인식과 관계 추출을 동시에 학습하고 수행하는 End-to-End 방식의 모델과 문장 수준 관계 추출을 넘어서 문서 수준의 관계를 추출하는 모델의 연구가 활발히 진행되고 있다. 본 논문에서는 End-to-End 방식의 문서 수준 관계 추출 모델인 Joint Entity Level Relation Extractor(JEREX) 모델에 Structured Self-Attention Network(SSAN)를 결합한 관계추출 모델을 제안한다. 실험 결과, 기존 JEREX 모델 보다 JEREX와 SSAN을 결합한 모델이 1.41% 높은 성능을 보였다.
1. 서 론
관계 추출은 문장에서 나타난 개체명 쌍(Entity Pair)의 관계(Relation)을 판별하는 태스크이며, 개체명 쌍은 관계의 주체(Subject)와 대상(Object)에 해당한다. 관계 추출은 비 구조적인 자연어 문장에서 나타난 관계의 주체와 대상으로 구성된 Triple(주어, 관계, 목적어)을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있다. 또한 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조적으로 표현된 정보는 자연어로 표현된 정보보다 기계가 해석하기 수월하기 때문에 질의응답, 구조화된 검색, 요약과 같은 자연어 처리 작업에 활용될 수 있다.
기존 관계 추출 연구는 문장 수준 관계 추출에 중점을 두고 연구가 진행되었다[1]. 최근에는 문장 수준을 넘어서는 문서 수준 관계 추출 연구가 진행되고 있으며, 이를 통해 문장 경계를 넘어 여러 문장 간에 존재하는 관계를 추출하는 것이 가능하다[1][2].
기존 관계 추출 연구에서는 주로 파이프라인 방식(2단계 방식)을 주로 이용하였다. 1단계인 개체명 인식기가 텍스트에서 개체를 추출하고, 추출된 개체 사이에 쌍 관계가 존재하는지 2단계인 관계 분류(Relation Classification)에서 판단한다. 그러나 이러한 파이프라인 방식은, 1단계인 개체명 인식에서 오류가 나는 경우, 이를 2단계인 관계 분류 단계에서 수정할 수 없으며, 개체명 인식 단계에서 관계 분류 단계의 정보를 사용할 수 없다는 단점이 있다. 이러한 문제를 해결하기 위해서 최근에는 개체명 인식과 관계 분류를 동시에 처리하는 End-to-end 방식과 Joint Learning 방식이 활발히 연구되고 있다[1].
본 논문에서는 End-to-End 방식의 문서 수준 관계 추출 모델인 Joint Entity-Level Relation Extractor(JEREX) 모델의 성능을 향상시키기 위해서, 외부 언어분석기(spaCy)의 개체명 인식 정보와 상호 참조 해결 정보를 추가로 입력하는 모델을 제안하며, 이를 위해 기존의 JEREX 모델의 Self-attention 부분에 Structured Self-Attention Network(SSAN)를 추가하였다.
2. 관련 연구
2.1 JEREX (‘Joint Entity-Level Relation Extractor’) [1]
JEREX는 개체명 인식과 상호참조해결, 엔티티 수준의 관계 추출을 결합한 다중 작업(multi task) 모델이다[1]. 이 모델은 문서 수준 관계 추출 데이터인 DocRED와 상호 참조 클러스터 정보를 사용하여 개체명 인식과 상호참조해결, 관계 추출을 동시에 학습하고 수행하는 Joint Learning 기술을 이용하였다.
그림 1은 JEREX 모델의 구조를 나타낸다. 그림 1에서 볼 수 있듯이, JEREX는 동일한 인코더 및 멘션 표현을 기반으로 하고 Joint Learning 방식으로 훈련되는 4개의 태스크로 구성된다: 1) 엔티티 멘션 추출, 2) 상호 참조 해결, 3) 엔티티 분류, 4) 관계 분류. 또한, 문서 인코딩을 위한 단일 BERT 인코더를 공유하고, 엔티티 분류와 관계 분류 모두 다중 인스턴스 학습(Multi-Instance Learning)을 사용한다. 엔티티 멘션 추출 단계에서는 스팬 기반 방식을 사용하고, 상호 참조 해결 단계를 통해 추출된 멘션을 엔티티로 그룹화한다. 엔티티 분류 단계에서는 각 엔티티를 ‘PER’이나 ‘LOC’등의 개체 유형으로 분류한다. 마지막으로 관계 분류 단계에서 엔티티 쌍에 관계 유형을 분류하여 할당한다.

2.2 SSAN (‘Structured Self Attention Network’) [2]
SSAN은 문서에서 나타나는 다양한 종류의 멘션의 의존성(개체명 및 상호참조해결 정보)을 엔티티 구조(Entity structure)로 표현하고 이를 Self-attention 메커니즘 내에서 이러한 멘션의 의존성을 모델링하였다[2]. SSAN의 가장 큰 특징인 엔티티 구조(Entity structure)는 다음과 같이 정의된다: 1) Intra + coref : 동일한 문장 내에서의 동일한 엔티티 2) Intra + relate : 동일한 문장 내에서의 함께 출현한 엔티티 3) Inter + coref : 동일하지 않은 문장에서 출현한 동일한 엔티티 4) Inter + relate : 동일하지 않은 문장에서 관계가 있는 엔티티 5) IntraNE : 동일한 문장 내에서 함께 출현하고 엔티티가 아닌 것 6) NA : 동일하지 않은 문장에서 엔티티가 아닌 것 (중요하지 않다고 판단한다.) SSAN은 문서 수준 관계 추출을 위해 위에서 정의된 엔티티 구조를 이용하여 Self-attention 메커니즘 내에 바이어스 값을 더해주어 멘션 간의 의존성을 모델링한다.
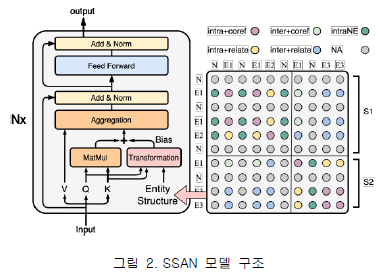
그림 2에서 볼 수 있듯이, 왼쪽은 구조화된 self-attention의 기본 요소를 나타내고 오른쪽은 엔티티 구조를 나타낸다. 위 그림은 S1, S2의 두 문장과 E1, E2, E3의 세 가지 엔티티로 예시를 보여주며, N은 엔티티가 아닌 토큰을 나타낸다. Structured Self Attention Network(SSAN)는 엔티티 멘션 사이의 의존성 외에도 엔티티 멘션과 엔티티 내 엔티티가 아닌 단어 사이의 의존성 또한 추가적으로 고려한다.

식 (1)은 Structured Self Attention Network(SSAN)의 Transformation 모듈에서 각각 쿼리와 키 벡터에 바이어스가 도입된 식을 나타낸다. 여기서 앞의 두 항은 훈련 가능한 신경층이며, 각각 쿼리 토큰 표현에 조건화 된 바이어스, 키 토큰 표현에 조건화 된 바이어스, 이전 바이어스를 나타낸다.

식 (2)는 Structured Self Attention의 전체적인 계산을 나타낸다. 이러한 transformation 계층은 다른 계층 또는 다른 Attention head와 공유하지 않는다.
3. JEREX + SSAN 통합 모델
본 논문에서는 End-to-End 방식의 문서 수준 관계 추출 모델인 Joint Entity-Level Relation Extractor(JEREX) 모델의 성능을 향상시키기 위해서, 외부 언어분석기(spaCy)의 개체명 인식 정보와 상호참조해결 정보를 추가로 입력하는 모델을 제안하며, 이를 위해, 그림 3과 같이 기존의 JEREX 모델의 인코더인 BERT 모델의 Self-attention 부분에 Structured Self-Attention Network(SSAN)를 추가하였다.

기존의 JEREX는 4개의 작업 요소(1. 엔티티 멘션 추출, 2. 상호 참조 해결, 3. 엔티티 분류, 4. 관계 분류)로 구성되며 이를 End-to-end 방식으로 공동 학습(Joint learning)한다. 하위 구성 요소에 단일 BERT 인코더를 공유하는데, 이 부분에 사전에 정의해 놓은 Structured Self Attention Network가 들어가서 BERT의 Self-Attention이 수행될 수 있도록 했다. JEREX의 학습에는 기존에 사용되었던 DocRED 데이터 셋을 사용하였으며, SSAN의 입력으로는 DocRED 데이터 셋에 외부 언어 분서기인 spaCy를 수행하여 얻은 오류가 포함된 개체명 인식 및 상호 참조 해결 결과를 사용하였다.
BERT 모델은 BERT-Base Cased 모델을 사용하였으며, 학습은 총 20 epoch을 수행하였다[1].
4. 실험
4.1 실험 데이터
JEREX와 SSAN이 결합된 모델의 학습 및 평가를 위해 문서 수준의 관계 추출 데이터인 DocRED (A Large-Scale Document-Level Relation Extraction Dataset)을 사용했다[3]. DocRED는 Wikipedia와 Wikidata로 구성된 문서 단위 관계 추출 데이터 셋으로, 원본 DocRED 데이터 셋은train (3053문서), dev (1000문서), test (1000문서)로 구성된다. 본 논문에서는 종단 간 시스템을 평가하기 위해 train과 dev 데이터 셋을 병합하여 새롭게 데이터 셋을 분할한다. 실험 시 train (3008문서), dev (300문서), test (700문서)를 무작위로 샘플링해서 사용하였다.
4.2 실험 결과
본 논문에서는 관계 추출의 성능 측정을 위해 F1_micro 지표를 사용하였다.
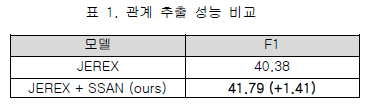
표 1은 Joint Learning을 사용한 관계 추출 모델인 JEREX와 JEREX에 SSAN를 결합한 모델의 평가셋에서의 관계 추출 성능을 나타낸다. 본 논문에서 제안한 JEREX+SSAN 모델의 성능이 JEREX 모델의 성능보다 1.41% 높은 것을 볼 수 있다.

표 2는 JEREX의 3개의 작업 요소인 엔티티 멘션 추출(Mention Localization), 상호 참조 해결(Coreference Resolution), 엔티티 분류(Entity Classification)의 개별 성능을 나타낸다. 기존 JEREX 모델에 외부 언어 분석기(spaCy)의 오류가 포함된 분석 결과를 SSAN을 통해 입력해 준 JEREX+SSAN 모델이 모든 작업 요소에서 성능이 향상되는 것을 볼 수 있다. 이는 오류가 포함된 외부언어분석기(spaCy)의 분석 결과 정보가 JEREX의 3개 작업 요소에 도움이 되기 때문이라고 판단된다.
5. 결론 및 향후 연구
본 논문에서는 End-to-End 방식의 문서 수준 관계 추출 모델인 Joint Entity-Level Relation Extractor(JEREX) 모델의 성능을 향상시키기 위해서, 외부 언어분석기(spaCy)의 개체명 인식 정보와 상호참조해결 정보를 추가로 입력하는 모델을 제안하며, 이를 위해 기존의 JEREX 모델의 인코더인 BERT 모델의 Self-attention 부분에 Structured Self-Attention Network(SSAN)를 추가하였다. 실험 결과, 본 논문에서 제안한 JEREX+SSAN 모델이 JEREX 모델보다 1.41% 높은 성능을 보였다.
향후 연구로는 JEREX와 SSAN가 결합된 모델에 의존구문분석 정보를 추가함으로써 관계 추출의 성능을 개선할 계획이다.
참 고 문 헌
[1] Markus Eberts, Adrian Ulges “An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning” EACL, eprint arXiv:2102.05980, 2021
[2] Benfeng Xu, Quan Wang, Yajuan Lyu, Yong Zhu, Zhendong Mao “Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction”AAAI, eprint arXiv:2102.10249, 2021
[3] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, Maosong Sun “DocRED: A Large-Scale Document-Level Relation Extraction Dataset”ACL, eprint arXiv:1906.06127, 2019