
[간단 내용 정리]
우리는 사전 작성 단계를 자동화하는 새로운 시스템인 스톰을 제안합니다. 스톰은 주제를 다시 검색하고 LLM을 사용하여 날카로운 질문을 던지고 인터넷에서 신뢰할 수 있는 정보를 다시 검색하여 개요를 만듭니다.
LLM으로 긴~ 형식의 아티클(like 위키피디아)을 처음부터 작성한다.
→ 다양한 분야의 전문가 관점 답변을 거친 뒤, 합성하여 글쓰기를 한다.
본격적으로 작성하기 전에 웹 조사를 하고 개요를 어떻게 쓸건지 준비하는 과정을 거친다.
(1) 다양한 관점에서 사전 작성 단계를 모델링 및 사전조사
(2) 그 다양한 전문가들이 답변을 하기 위해 신뢰할 수 있는 인터넷 자료들에 기반하여 대화를 시뮬레이션한다.
(3) 수집된 정보를 큐레이팅하여 문서를 작성한다. (검색 및 다각적인 질문 요청을 통한 주제 개요 합성)
좋은 긴 글을 작성하기 위해서는 사전 준비 단계를 철저히 해야 한다.
문서가 미리 제공된다고 가정하거나, 기사 개요가 제공된다고 가정하고 각 섹션을 확장하는 식으로 연구되는 방식은 일반적으로 적용되기 어렵다.
(성능 평가)
고품질 위키백과 기사 데이터 세트인 FreshWiki를 큐레이팅하고 개요 평가를 공식화하여 작성 전 단계를 평가
추가적으로, 위키백과 편집자(human)의 피드백을 추가로 수집한다. → 출처 편향성 및 과잉 연관을 막기 위함.
RAG에 의해 생성된 기사와 비교했을 때 스톰은 더 조직적이고 커버리지가 넓은 것을 확인. (25%P, 10%P)
직접 프롬프트와 같은 간단한 접근 방식으로는 계획 용량이 제한적. 반면, 스톰은 시뮬레이션 대화에서 관점 안내 질문을 통해 주제를 연구.
다양한 관점은 다양한 질문으로 이어지고, 심층 질문을 공식화하려면 반복적인 실험이 필요하다. → 다단계 접근 방식 제안.
작업1. 개요, 즉 다단계 섹션 목록을 생성하고 일련을 참조 문서를 수집하기 위한 작업을 수행.
작업2. 개요와 참조를 사용하여 전체 길이의 기사를 작성한다.
step1. 그림1 B에서 유사한 주제에 대해 위키피디아 기사를 검색하고 분석하여 다양한 관점의견을 발견하고, 다음 질문에 대한 특정 관점으로 LLM을 의인화한다.(전문가)
step2. 반복 실행을 통한 후속 질문을 도출하기 위해 생성된 질문에 대한 답이 인터넷에 기반하는 멀티 턴 변환을 시뮬레이션 한다. (그림 C)
step3. 마지막으로 STORM의 내부지식과 수집된 정보를 기반으로 섹션별로 확장하여 전체 길이의 위키피디아와 유사한 기사를 개발할 수 있는 개요를 만든다.
pretrain시, 데이터 유출을 방지하기 위해 최신 고품질 위키백과 기사를 큐레이팅하는 FreshWiki 데이터셋을 사용하여 모델을 평가한다. 사람이 작성한 기사에 대한 개요 품질을 평가하기 위한 지표도 정의. 그래야 비교를 하지.
주제 t가 주어지면 참조 집합 R을 찾음.
각 문장 S^i 가 R^2의 문서 목록을 인용하는 전체 길이의 문서 S=S1,S2..Sn을 생성한다.
최신 LLM은 일반적으로 위키피디아 텍스트에 대해 학습됨 추가 연구기술이 필요.
2022년 2월부터 20233년 9월까지 매월 편집 횟수를 기준으로 가장 많이 편집된 상위 100개 페이지에 초점을 맞춥니다. 고품질 참조를 보장하기 위해 이러한 기사를 필터링하여 ORES4에서 평가한 B급 이상의 품질을 가진 기사만 유지합니다.
고품질 위키백과 기사에는 일반적으로 구조화된 데이터(예: 표)가 포함되어 있고 다중 모달이지만, 작업을 단순화하기 위해 데이터 세트를 구성할 때 일반 텍스트 구성 요소만 고려합니다. 기사의 텍스트만 고려.
전체 글 S, S를 두 개로 분해함.
쓰기 전 단계 : 시스템이 다단계 섹션 제목 목록으로 정의된 개요 O를 만들어야 한다.
쓰기 단계 : 시스템이 주제 t, 참조 R, 개요 O를 사용하여 S를 작성한다.
(step1) 3.1, 3.2 → 그래서 주제를 조사하고 아웃라인생성 이걸 구체적으로 어떻게 하는가!
(3.1)
입력된 주제 t가 주어지면 스톰은 유사한 주제의 기존 기사를 조사하여 서로 다른 관점을 발견하고 이러한 관점을 사용하여 질문 요청 프로세스를 제어합니다. 특히, 스톰은 LLM에 관련 주제 목록을 생성하도록 요청한 다음 해당 위키피디아 API7(그림 2 1)을 통해 해당 기사를 얻을 수 있는 경우 해당 위키피디아 기사에서 내용 표를 추출합니다.
추출된 내용 표를 연결하여 컨텍스트를 생성하여 LLM이 t에 대한 포괄적인 기사에 총체적으로 기여할 수 있는 N개의 관점 P = {p1, ..., pN}을 식별하도록 유도합니다(그림 2). t에 대한 기본 정보도 다루도록 하기 위해 P0을 "주제에 대한 기본 사실을 광범위하게 다루는 데 중점을 둔 기본 사실 작성자"로 P에 추가합니다. 각 퍼스펙티브 p ∈ P는 질문 과정에서 LLM을 병렬로 안내하는 데 활용됩니다.
(3.2)
주제에 대한 포괄적인 답변으로부터 새로운 답변을 생성하는 경우가 많다. (꼬리에 꼬리를 물어 깊이 들어가는 질문처럼)
이 프로세스를 적용하기 위해 스톰은 위키백과 작성자와 전문가 간의 대화를 시뮬레이션 한다.
대화 i번째 라운드에서 LLM 기반 위키백과 작성자는 주제 t, 할당된 관점 p ∈ P, 대화 기록 {q1,a1,...,qi-1,ai-1}을 기반으로 단일 질문 qi를 생성하며, 여기서 aj는 초음파 처리된 전문가의 답변을 거부합니다. 대화 기록을 통해 LLM은 주제에 대한 이해를 업데이트하고 후속 질문을 할 수 있습니다. 실제로는 대화를 최대 M라운드로 제한합니다.
대화 기록이 사실 정보를 제공하는지 확인하기 위해 인터넷의 신뢰할 수 있는 출처를 사용하여 각 쿼리에 대한 답변 ai를 접지합니다. qi는 복잡할 수 있으므로 먼저 LLM에 qi를 검색 쿼리 집합으로 분류하도록 요청하고(그림 2 4), 검색된 결과는 위키피디아 가이드라인8에 따라 규칙 기반 필터를 사용하여 평가하여 신뢰할 수 없는 출처를 제외합니다(그림 2 5). 마지막으로, LLM은 신뢰할 수 있는 출처를 합성하여 답변 ai를 생성하고, 이러한 출처는 전체 기사 생성을 위해 R에도 추가됩니다(§ 3.4).
(step2) 3.3 → 이제 조사한 정보들을 바탕으로 S를 작성 → 이건 구체적으로 어떻게 진행되는가!
(3.3) 개요
N + 1개의 시뮬레이션 대화({C0, C1, ..., CN })를 통해 주제를 철저히 조사한 후, 스톰은 실제 작성이 시작되기 전에 개요를 작성합니다. LLM에 대한 내부 지식을 최대한 활용하기 위해 먼저 모델이 주제 t만 주어진 개요 OD 초안을 생성하도록 유도합니다(그림 2 7). OD는 일반적이지만 체계적인 프레임워크를 제공합니다. 그런 다음 LLM에 주제 t, 개요 초안 OD 및 시뮬레이션된 대화 {C0, C1, ..., CN }에 대한 프롬프트를 표시하여 개요를 개선합니다(그림 2). 그 결과 전체 길이의 글을 작성하는 데 사용될 개선된 개요 O가 생성됩니다.
(3.4) 전체 아티클 작성
수집된 참조 R과 사전 작성 단계에서 개발된 개요 O를 기반으로 전체 길이의 글을 섹션별로 구성할 수 있습니다. 일반적으로 LLM의 컨텍스트 창 내에 전체 R을 맞추는 것은 불가능하기 때문에 모든 수준의 하위 섹션의 섹션 제목과 제목을 사용하여 문장-BERT 임베딩에서 계산된 의미 유사성을 기반으로 R에서 관련 문서를 검색합니다. 그런 다음 관련 정보가 있으면 LLM에서 인용문이 있는 섹션을 생성하라는 메시지가 표시됩니다. 모든 섹션이 생성되면 이 섹션을 연결하여 전체 길이의 글을 구성합니다. 섹션이 병렬로 생성되므로 일관성을 개선하기 위해 연결된 글로 LLM에 반복되는 정보를 삭제하도록 요청합니다. 또한 위키피디아의 스타일 규범에 따라 LLM은 전체 글의 요약을 합성하는 데도 활용되며, 처음에 리드 섹션을 구성합니다.
(모듈)
- 지식 큐레이션 모듈: 주어진 주제에 관한 광범위한 정보를 수집합니다.
- 개요 생성 모듈: 정리된 지식에 대한 계층적 개요를 생성하여 수집된 정보를 구성합니다.
- 기사 생성 모듈: 수집된 정보로 생성된 개요를 채웁니다.
- 기사 다듬기 모듈: 더 나은 프레젠테이션을 위해 작성된 기사를 다듬고 향상시킵니다.
[논문 본문 번역본]
[Abstract]
우리는 대형 언어 모델을 적용하여 위키피디아 페이지와 비슷한 폭과 깊이로 근거가 있고 체계적인 긴 형식의 아티클을 처음부터 작성하는 방법을 연구합니다. 이 덜 탐색된 문제는 쓰기 전에 주제를 조사하고 개요를 준비하는 방법을 포함하여 쓰기 전 단계에서 새로운 과제를 제기합니다. 우리는 검색 및 다각적인 질문 요청을 통한 주제 개요 합성을 위한 글쓰기 시스템인 스톰을 제안합니다. 스톰은 (1) 주어진 주제를 연구하는 데 있어 다양한 관점을 발견하는 사전 작성 단계를 모델링하고, (2) 서로 다른 관점을 가진 작가가 신뢰할 수 있는 인터넷 출처에 기반한 주제 전문가에게 질문을 던지는 대화를 시뮬레이션하고, (3) 수집된 정보를 큐레이팅하여 개요를 작성합니다.
평가를 위해 최근 고품질 위키백과 기사 데이터 세트인 FreshWiki를 큐레이팅하고 개요 평가를 공식화하여 작성 전 단계를 평가합니다. 숙련된 위키백과 편집자의 피드백을 추가로 수집합니다. 개요 기반 검색 증강 기준에 의해 생성된 기사와 비교했을 때, 더 많은 스톰의 기사는 (절대적으로 25% 증가) 조직적이고 (10% 증가) 커버 에이지가 넓은 것으로 간주됩니다. 또한 전문가 피드백은 출처 편향성 전이 및 관련 없는 사실의 과잉 연관과 같이 근거가 있는 긴 기사를 생성하기 위한 새로운 과제를 식별하는 데 도움이 됩니다.
[1. Introduction]
대형 언어 모델(LLM)은 인상적인 글쓰기 기능을 입증했지만(양 외, 2023년; 파블릭 외, 2023년; 웬즐라프와 스페이스, 2022년; 피트리아, 2023년), 전체 위키피디아 페이지와 같은 근거 있는 긴 형식의 기사를 작성하는 데 어떻게 사용할 수 있을지는 불분명합니다. 독자에게 주제에 대해 조직화된 방식으로 알리려는 이러한 노출형 글쓰기는 실제 글쓰기 프로세스가 시작되기도 전에 사전 글쓰기 단계(Rohman,1965)에서 철저한 연구와 계획이 필요합니다(Rohman,1965). 그러나 위키피디아 기사를 생성하기 위한 이전 작업(Banerjee와 Mitra, 2015; Minguillon 외, 2017; Liu 외, 2018; Fan and Gardent, 2022)은 일반적으로 사전 작성 단계를 우회했습니다: 예를 들어, Liu 외(2018)는 참고 문서가 미리 제공된다고 가정하는 반면, Fan과 Gardent(2022)는 기사 개요가 제공된다고 가정하고 각 섹션을 확장하는 데 집중합니다. 참고 문헌 수집과 제작 개요는 외부 출처를 식별, 평가 및 구성하는 고급 정보 리터러시 기술(도일, 1994)을 요구하기 때문에 이러한 가정은 일반적으로 적용되지 않으며, 이는 숙련된 작가도 어려운 작업입니다. 이 프로세스를 자동화하면 개인이 주제에 대해 심층 학습을 시작할 수 있고, 노출형 글쓰기에 필요한 값비싼 전문가 시간을 크게 줄일 수 있습니다.

그림 1: 우리는 기사를 작성하기 전에 사전 작성 단계가 필요한 위키피디아와 유사한 기사를 처음부터 작성하는 방법을 살펴봅니다. 이 단계에서는 직접 프롬프트와 같은 간단한 접근 방식으로는 계획 용량이 제한적입니다. 반면, 스톰은 시뮬레이션 대화에서 관점 안내 질문을 통해 주제를 연구합니다.
우리는 위키피디아와 유사한 기사를 처음부터 생성하는 방법에 초점을 맞춰 이러한 과제를 탐구합니다. 우리는 이 문제를 두 가지 작업으로 분해합니다. 첫 번째는 개요, 즉 다단계 섹션 목록을 생성하고 일련의 참조 문서를 수집하기 위한 연구를 수행하는 것입니다. 두 번째는 개요와 참조를 사용하여 전체 길이의 아티클을 생성합니다. 이러한 작업 분해는 일반적으로 사전 작성, 초안 작성 및 수정 단계를 포함하는 인간의 글쓰기 프로세스를 반영합니다(Rohman, 1965; Munoz-Luna, 2015).
사전 학습된 언어 모델은 본질적으로 풍부한 지식을 전제로 하기 때문에, 직접적인 접근 방식은 개요 또는 전체 기사를 생성하기 위해 파라메트릭 지식에 의존하는 것입니다(Direct Gen). 그러나 이러한 접근 방식은 특히 롱테일 주제를 다루는 데 있어 세부 사항과 환각의 부족으로 인해 제한됩니다(Xu 외, 2023). 이는 외부 소스를 활용하는 것의 중요성을 강조하며, 현재 전략에는 검색 증강 생성(RAG)이 포함되는 경우가 많으며, 이는 단순한 주제 검색을 통해 많은 정보를 드러낼 수 없기 때문에 사전 작성 단계에서 주제를 연구하는 문제로 되돌아가는 경우가 많습니다.
인간 학습 이론(Tawfik et al., 2020; Booth et al., 2003)은 정보 획득에서 효과적인 질문을 하는 것을 강조합니다. 명령어 조정 모델(Ouyang et al., 2022)은 질문을 직접 생성하도록 유도할 수 있지만, 일반적으로 주제에 대한 표면 수준의 사실만 다루는 기본적인 "무엇", "언제" 및 "어디" 질문(그림 1(A))을 생성한다는 것을 발견했습니다. LLM에게 더 나은 연구를 수행할 수 있는 역량을 부여하기 위해 검색 및 다각적인 질문 요청을 통한 주제 개요 합성을 위한 스톰 패러다임을 제안합니다.
스톰의 설계는 두 가지 가설을 기반으로 합니다: (1) 다양한 관점은 다양한 질문으로 이어지고, (2) 심층 질문을 공식화하려면 반복적인 연구가 필요합니다. 이러한 가설을 기반으로 STORM은 새로운 다단계 접근 방식을 채택합니다. 먼저 유사한 주제에서 위키피디아 기사를 검색하고 분석하여 다양한 관점을 발견한 다음 질문에 대한 특정 관점으로 LLM을 의인화합니다(그림 1(B)). 다음으로 반복 연구를 위한 후속 질문을 도출하기 위해 STORM은 생성된 질문에 대한 답이 인터넷에 기반하는 멀티 턴 변환을 시뮬레이션합니다(그림 1(C)). 마지막으로, STORM의 내부 지식과 수집된 정보를 기반으로 STORM은 섹션별로 확장하여 전체 길이의 위키피디아와 유사한 기사를 개발할 수 있는 개요를 만듭니다.
사전 교육 중 데이터 유출을 방지하기 위해 최신 고품질 위키백과 기사를 큐레이팅하는 FreshWiki 데이터 세트(§2.1)를 사용하여 스톰을 평가합니다.1 사전 작성 단계의 연구를 용이하게 하기 위해 사람이 작성한 기사에 대한 개요 품질을 평가하기 위한 지표를 정의합니다.
또한 숙련된 위키피디아 편집자 그룹을 전문가 평가를 위해 초대했습니다. 편집자들은 특히 기사의 폭과 구성과 관련하여 스톰이 개요 기반 RAG 기준선을 능가한다는 사실을 발견했습니다. 또한 (1) 인터넷의 편향성이 생성된 기사에 영향을 미치고, (2) LLM이 관련 없는 사실 간의 연결을 조작하는 경우를 포함하여 향후 연구를 위한 과제를 확인했습니다. 이러한 과제는 근거 없는 글쓰기 시스템에 대한 새로운 지평을 제시합니다.
주요 기여 사항은 다음과 같습니다:
• LLM 시스템이 처음부터 긴 형식의 근거 기사를 생성하는 능력과 특히 사전 작성 과제를 평가하기 위해 FreshWiki 데이터 세트를 큐레이팅하고 개요 및 최종 기사 품질에 대한 평가 기준을 설정합니다.
• 우리는 사전 작성 단계를 자동화하는 새로운 시스템인 스톰을 제안합니다. 스톰은 주제를 다시 검색하고 LLM을 사용하여 날카로운 질문을 던지고 인터넷에서 신뢰할 수 있는 정보를 다시 검색하여 개요를 만듭니다.
• 자동 평가와 인간 평가는 모두 우리 접근 방식의 효과를 입증합니다. 전문가 피드백을 통해 근거가 있는 긴 형태의 기사를 생성하는 데 있어 새로운 과제를 발견할 수 있습니다.
[2. FreshWiki]
우리는 위키피디아와 유사한 기사를 처음부터 생성하여 관련 정보를 수집하고 큐레이션하는 요구 사항이 많은 하위 작업("연구")을 포함하는 사전 작성 단계(Rohman, 1965)에 중점을 두고 연구합니다. 이는 일부 교육자들이 위키피디아 기사 작성을 학문적 훈련을 위한 교육적 연습으로 간주하도록 유도한 인간 글쓰기 접근 방식을 모델링합니다(Tardy, 2010).
표 1은 위키백과 생성에 대한 이전 벤치마크와 우리의 작업을 비교합니다. 기존 작업은 일반적으로 짧은 스니펫(예: 한 문단)의 생성, 좁은 범위 내(예: 특정 도메인 또는 두 개) 또는 명시적인 개요 또는 참조 문서가 제공되는 시기를 평가하는 데 중점을 두었습니다. 주목할 만한 예는 위키섬(Liu et al., 2018)으로, 참고 문서와 관련하여 위키피디아 아티클 생성을 다중 문서 요약 문제로 취급합니다.

표 1: 기존 문헌의 다양한 위키백과 생성 설정 비교. 한 단락을 생성할 때는 기사 개요가 필요하지 않습니다.
우리의 설정은 콘텐츠를 연구하고 큐레이팅하는 장기 형식 기반 쓰기 시스템의 기능을 강조합니다. 특히 주제 t가 주어지면 참조 R 집합을 찾아 각 문장 si가 R.2의 문서 목록을 인용하는 전체 길이의 문서 S = s1s2...sn을 생성하는 것이 작업입니다.
[2.1 The FreshWiki Dataset]
위키피디아와 유사한 새로운 글을 만들려면 유창한 글쓰기뿐만 아니라 훌륭한 연구 기술도 필요합니다. 최신 LLM은 일반적으로 위키피디아 텍스트에 대해 학습되므로 테스트하는 LLM의 학습 중단 후 생성되거나 매우 많이 편집된 최신 위키피디아 기사를 명시적으로 검색하여 데이터 유출을 완화합니다. 새로운 LLM이 등장하는 향후 날짜에도 프로세스가 반복될 수 있습니다.
날짜 기준을 적용하기 위해 2022년 2월부터 20233년 9월까지 매월 편집 횟수를 기준으로 가장 많이 편집된 상위 100개 페이지에 초점을 맞춥니다. 고품질 참조를 보장하기 위해 이러한 기사를 필터링하여 ORES4에서 평가한 B급 이상의 품질을 가진 기사만 유지합니다. 또한 목록 기사5와 하위 섹션이 없는 기사는 제외합니다. 고품질 위키백과 기사에는 일반적으로 구조화된 데이터(예: 표)가 포함되어 있고 다중 모달이지만, 작업을 단순화하기 위해 데이터 세트를 구성할 때 일반 텍스트 구성 요소만 고려합니다. 데이터 세트에 대한 자세한 내용은 부록 A에 나와 있습니다.
[2.2 Outline Creation and Evaluation]
전체 길이의 글은 생성하거나 평가하기 어렵습니다(Xu 외, 2023; 크리슈나 외, 2023). 인간 교육자는 학생들에게 학술 글쓰기를 가르칠 때 개요 단계(에릭슨과 메키탈로, 2015)에서 학생들을 감독하는 경우가 있는데, 이는 광범위한 개요가 주제에 대한 포괄적인 이해를 보여주고 전체 길이의 글을 작성할 수 있는 탄탄한 기반을 제공하기 때문입니다(Dietz와 Foly, 2019). 이에서 영감을 받아 S의 세대를 두 단계로 분해합니다. 쓰기 전 단계에서는 시스템이 다단계 섹션 제목 목록으로 정의된 개요 O를 만들어야 합니다6. 쓰기 단계에서는 시스템이 주제 t, 참조 R, 개요 O를 사용하여 전체 길이의 글 S를 작성합니다.
개요 커버리지를 평가하기 위해 소프트 리콜과 엔티 리콜이라는 두 가지 지표를 소개합니다. 이러한 지표는 근거 자료로 간주되는 인간이 작성한 글의 다단계 섹션 제목과 O. 이 두 가지 제목 집합의 요소 간에 정확한 일치가 불필요하다는 것을 인식하고, 문장-BERT(Reimers and Gurevich, 2019)에서 파생된 코사인 유사성(자세한 내용은 부록 C.1)을 사용하여 제목 소프트 리콜(Franti and Mariescu-Istoor, 2023)을 계산합니다. 또한 O.에서 다루는 인간이 작성한 글 제목에서 명명된 개체의 백분율로 정량화된 제목 개체 리콜을 계산합니다(Akbik et al., 2019). 우리는 FLAIR로 명명된 개체 인식 티온(NER)을 가진 개체를 추출합니다(Akbik et al.).
[3. Method]
효과적인 질문을 통해 주어진 주제를 조사하고(§3.1, §3.2) 아웃라인을 생성하여 사전 작성 단계를 자동화하는 스톰을 제시합니다(§3.3). 개요는 수집된 참조를 기반으로 한 전체 길이의 기사로 확장됩니다(§3.4). 그림 2는 스톰의 개요를 제공하며 부록 B에 유사 코드를 포함합니다.

그림 2: 사전 작성 단계를 자동화하는 스톰 개요. 주어진 주제부터 시작하여 관련 위키피디아 기사(1~2)를 조사하여 주제를 다루는 데 대한 다양한 관점을 파악합니다. 그런 다음 주어진 관점에 따라 안내된 질문을 하는 위키피디아 작가와 신뢰할 수 있는 온라인 출처에 기반한 전문가 간의 대화를 시뮬레이션합니다(3~6). 최종 개요는 LLM의 내재적 지식과 다양한 관점에서 수집된 대화를 기반으로 선별됩니다(7~8).
[3.1 Perspective-Guided Question Asking]
Rohman(1965)은 사전 글쓰기를 글쓰기 과정에서 발견하는 단계로 정의합니다. 다양한 이해관계자가 기업의 다양한 측면을 우선시하는 비즈니스의 이해관계자 이론(Freeman et al., 2010)과 마찬가지로, 서로 다른 관점을 가진 개인은 동일한 주제를 연구할 때 다양한 측면에 집중하고 다각적인 정보를 발견할 수 있습니다. 또한 특정 관점은 사전 지식의 역할을 하여 개인이 더 심층적인 질문을 할 수 있도록 안내할 수 있습니다. 예를 들어, 이벤트 기획자는 "2022 동계 올림픽 개막식"의 "교통수단 배치"와 "예산"에 대해 질문할 수 있지만, 일반인은 이벤트의 기본 정보에 대해 더 일반적인 질문을 할 수 있습니다(그림 1(A)).
입력된 주제 t가 주어지면 스톰은 유사한 주제의 기존 기사를 조사하여 서로 다른 관점을 발견하고 이러한 관점을 사용하여 질문 요청 프로세스를 제어합니다. 특히, 스톰은 LLM에 관련 주제 목록을 생성하도록 요청한 다음 해당 위키피디아 API7(그림 2 1)을 통해 해당 기사를 얻을 수 있는 경우 해당 위키피디아 기사에서 내용 표를 추출합니다. 이러한 내용 표를 연결하여 컨텍스트를 생성하여 LLM이 t에 대한 포괄적인 기사에 총체적으로 기여할 수 있는 N개의 관점 P = {p1, ..., pN}을 식별하도록 유도합니다(그림 2). t에 대한 기본 정보도 다루도록 하기 위해 P0을 "주제에 대한 기본 사실을 광범위하게 다루는 데 중점을 둔 기본 사실 작성자"로 P에 추가합니다. 각 퍼스펙티브 p ∈ P는 질문 과정에서 LLM을 병렬로 안내하는 데 활용됩니다.
[3.2 Simulating Conversations]
질문과 질문에 대한 이론(Ram, 1991)은 기존 질문에 대한 답변이 주제에 대한 보다 포괄적인 이해에 기여하지만 동시에 새로운 질문을 생성하는 경우가 많다는 점을 강조합니다. 이 역동적인 프로세스를 시작하기 위해 스톰은 위키백과 작성자와 주제 전문가 간의 대화를 시뮬레이션합니다. 대화 i번째 라운드에서 LLM 기반 위키백과 작성자는 주제 t, 할당된 관점 p ∈ P, 대화 기록 {q1,a1,...,qi-1,ai-1}을 기반으로 단일 질문 qi를 생성하며, 여기서 aj는 초음파 처리된 전문가의 답변을 거부합니다. 대화 기록을 통해 LLM은 주제에 대한 이해를 업데이트하고 후속 질문을 할 수 있습니다. 실제로는 대화를 최대 M라운드로 제한합니다.
대화 기록이 사실 정보를 제공하는지 확인하기 위해 인터넷의 신뢰할 수 있는 출처를 사용하여 각 쿼리에 대한 답변 ai를 접지합니다. qi는 복잡할 수 있으므로 먼저 LLM에 qi를 검색 쿼리 집합으로 분류하도록 요청하고(그림 2 4), 검색된 결과는 위키피디아 가이드라인8에 따라 규칙 기반 필터를 사용하여 평가하여 신뢰할 수 없는 출처를 제외합니다(그림 2 5). 마지막으로, LLM은 신뢰할 수 있는 출처를 합성하여 답변 ai를 생성하고, 이러한 출처는 전체 기사 생성을 위해 R에도 추가됩니다(§ 3.4).
[3.3 Creating the Article Outline]
N + 1개의 시뮬레이션 대화({C0, C1, ..., CN })를 통해 주제를 철저히 조사한 후, 스톰은 실제 작성이 시작되기 전에 개요를 작성합니다. LLM에 대한 내부 지식을 최대한 활용하기 위해 먼저 모델이 주제 t만 주어진 개요 OD 초안을 생성하도록 유도합니다(그림 2 7). OD는 일반적이지만 체계적인 프레임워크를 제공합니다. 그런 다음 LLM에 주제 t, 개요 초안 OD 및 시뮬레이션된 대화 {C0, C1, ..., CN }에 대한 프롬프트를 표시하여 개요를 개선합니다(그림 2). 그 결과 전체 길이의 글을 작성하는 데 사용될 개선된 개요 O가 생성됩니다.
[3.4 Writing the Full-Length Article]
수집된 참조 R과 사전 작성 단계에서 개발된 개요 O를 기반으로 전체 길이의 글을 섹션별로 구성할 수 있습니다. 일반적으로 LLM의 컨텍스트 창 내에 전체 R을 맞추는 것은 불가능하기 때문에 모든 수준의 하위 섹션의 섹션 제목과 제목을 사용하여 문장-BERT 임베딩에서 계산된 의미 유사성을 기반으로 R에서 관련 문서를 검색합니다. 그런 다음 관련 정보가 있으면 LLM에서 인용문이 있는 섹션을 생성하라는 메시지가 표시됩니다. 모든 섹션이 생성되면 이 섹션을 연결하여 전체 길이의 글을 구성합니다. 섹션이 병렬로 생성되므로 일관성을 개선하기 위해 연결된 글로 LLM에 반복되는 정보를 삭제하도록 요청합니다. 또한 위키피디아의 스타일 규범에 따라 LLM은 전체 글의 요약을 합성하는 데도 활용되며, 처음에 리드 섹션을 구성합니다.
[4. Experiments]
[4.1 Article Selection]
스톰은 복잡한 주제를 조사하고 세부 개요에서 긴 글을 작성할 수 있습니다. 그러나 이 통제된 실험에서는 최종 출력을 최대 4000개의 토큰(약 3000단어)으로 제한합니다. 의미 있는 비교를 위해 FreshWiki 데이터 세트에서 사람이 쓴 글이 3000단어를 넘지 않는 100개의 샘플을 무작위로 선택합니다(§ 2.1 참조).
[4.2 Automatic Metrics]
§ 2.2에서 논의한 바와 같이, 제목 소프트 리콜 및 제목 개체 리콜을 계산하여 작성 전 단계를 평가하기 위한 개요 품질을 평가합니다. 리콜 점수가 높을수록 사람이 작성한 기사에 비해 더 포괄적인 개요를 의미합니다.
전체 기사 품질을 평가하기 위해 ROUGE 점수(Lin, 2004)를 채택하고 FLAIR NER 결과를 기반으로 기사 수준에서 개체 리콜을 계산합니다. 또한 위키피디아 기준 9를 기반으로 (1) 관심 수준, (2) 일관성 및 조직, (3) 관련성 및 초점, (4) 커버리지, (5) 검증 능력 측면에서 기사를 평가합니다. 측면 (1)-(4)의 경우, 13B 평가자인 프로메테우스(Kim et al., 2023)를 사용하여 숙련된 위키피디아 편집자 2명과 공동 개발한 5점 루브릭을 기반으로 아티클을 채점합니다(부록 C.2 참조). 검증 가능성을 위해 Gao et al. (2023)의 정의를 기반으로 인용 리콜 및 인용 정밀도를 계산합니다. 미스트랄 7B- 인스트럭트(Jiang et al., 2023a)를 사용하여 인용 구절이 생성된 문장을 포함하는지 여부를 검토합니다.
[4.3 Baseline]
이전 작업은 서로 다른 설정을 사용하고 LLM을 사용하지 않기 때문에 직접 비교하기 어렵습니다. 대신 다음 세 가지 LLM 기반 기준선을 사용합니다.
1. 다이렉트 젠은 LLM이 윤곽선을 생성하도록 직접 유도하는 기준선으로, 전체 길이의 기사를 생성하는 데 사용됩니다.
2. RAG는 주제와 함께 검색하고 검색된 결과를 주제 t와 함께 사용하여 개요 또는 전체 기사를 생성하는 검색 증강 세대 기준선입니다.
3. 윤곽선 기반 RAG(oRAG)는 윤곽선 생성에서 RAG와 동일하지만 섹션 제목으로 추가 정보를 검색하여 섹션별 기사를 생성합니다.
[4.4. STORM Implementation]
우리는 DSPy 프레임워크(Khattab et al., 2023)를 사용하여 제로 샷 프롬프트로 STROOM을 구축합니다. 부록 B에는 의사 코드와 해당 프롬프트가 포함되어 있습니다. STROOM의 하이퍼파라미터 N과 M은 모두 5로 설정되어 있습니다. 질문을 할 때는 채팅 모델 gpt-3.5-turbo을 사용하고 STROOM의 다른 부분에는 gpt-3.5-turbo-instruct을 사용합니다. 또한 개요 초안 작성 및 개선을 위해 gpt-4를 사용하여 실험합니다(그림 2 - 8). 보고된 결과의 경우, 제안된 파이프라인은 다른 검색 엔진과 호환되지만 STROOM의 시뮬레이션된 주제 전문가는 You.com 검색 API10에 기반하고 있습니다. 검색 결과에서 실측 자료 위키백과 문서는 제외됩니다.
최종 기사 생성의 경우, 인용이 포함된 텍스트를 생성할 때 출처에 충실하지 않으므로 gpt-3.5를 사용한 결과만 보고합니다(Gao et al., 2023). 모든 실험에서 온도를 1.0으로, top_p를 0.9로 설정했습니다.

표 2: 자동 기사 품질 평가 결과. †은 STOM과 최상의 기준, 즉 ORAG 간의 쌍을 이루는 t-검정에서 유의미한 차이(p < 0.05)를 나타냅니다. 루브릭 등급은 1-5 척도를 사용합니다.

표 3: 개요 품질 평가 결과(%). †는 스톰과 베이스라인 간의 쌍체 t-검정에서 유의미한 차이(p < 0.05)를 발견하지 못했습니다.
[Results and Analysis]
[5.1 Main Results]
개요 커버리지를 프록시로 사용하여 사전 작성 단계를 평가합니다(§ 2.2 참조). 표 3은 헤드라인 소프트 리콜 및 개체 리콜을 보여줍니다. LLM(Direct Gen)이 직접 생성한 개요는 이미 높은 헤드라인 소프트 리콜을 입증하고 있으며, 이는 풍부한 매개변수 지식을 통해 주제의 높은 수준의 측면을 파악하는 LLM의 능력을 나타냅니다. 그러나 STOM은 주제를 연구하기 위해 효과적인 질문을 함으로써 더 많은 주제별 측면을 다루는 더 높은 리콜 개요를 만들 수 있습니다. 특히 RAG는 추가 정보를 활용하지만 컨텍스트 창에 체계적이지 않은 정보를 제시하면 약한 모델, 즉 GPT-3.5의 경우 개요 생성이 더 어려워져 성능이 저하됩니다. RAG 베이스라인의 한계를 테스트하기 위해 RAG에서 생성한 개요부터 시작하여 섹션 제목을 검색 쿼리로 사용하여 더 많은 소스를 수집하고 새로 수집한 소스를 초기 개요와 함께 LLM에 입력하여 검색된 소스를 더욱 확장합니다. 이 수정된 접근 방식을 표 3에서 "RAG-확장"이라고 합니다. 실험 결과에 따르면 추가적인 검색 및 개선 라운드를 통해 RAG에서 생성한 개요를 개선할 수 있지만, 제안한 STOM은 여전히 성능을 능가합니다.
우리는 전체 길이 기사 품질을 추가로 평가합니다. 표 2에서 볼 수 있듯이, oRAG는 RAG보다 훨씬 우수한 성능을 보이며 전체 길이 기사 생성을 구조화하는 데 개요를 사용하는 것의 효과를 강조합니다. 이 방법은 검색과 개요를 활용하는 데 있어 이점이 있음에도 불구하고 우리의 접근 방식은 여전히 이 방법을 능가합니다. 메카니즘을 묻는 효과적인 질문은 개체 리콜이 더 큰 기사를 향상시킵니다. 평가자 LLM은 또한 이러한 기사를 "관심 수준", "관련성 및 초점", "범위" 측면에서 훨씬 더 높은 점수로 평가합니다. 그럼에도 불구하고 평가자 LLM이 기계로 생성된 텍스트를 과대평가할 가능성을 인정합니다. 신중한 인간 평가(§ 6)에 따르면 스톰은 여전히 개선의 여지가 많은 것으로 나타났습니다.
이 작업은 주로 글쓰기 전 단계에 초점을 맞추고 인용문으로 텍스트를 생성하는 데 최적화되지는 않지만, 여전히 우리의 접근 방식으로 생성된 기사의 인용 품질을 검토합니다. 표 4에 보고된 바와 같이, 미스트랄 7B-명령 심사위원은 문장의 84.83%를 인용문으로 뒷받침합니다. Ap-pendix C.3은 지원되지 않는 문장을 조사하여 주요 문제가 존재하지 않는 내용을 환각하기보다는 부적절한 추론을 끌어내고 부정확한 구문 분석에서 비롯된 것임을 밝혀냈습니다.
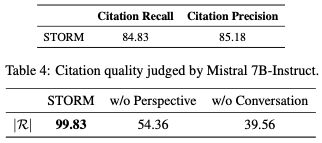
표 5: 다양한 방법으로 수집한 고유 참조의 평균 수(|R|).
[5.2 Ablation Studies]
§3에 소개된 바와 같이, 스톰은 특정 관점을 발견하고 멀티턴 대화를 시뮬레이션하여 LLM이 효과적인 질문을 하도록 유도합니다. 우리는 스톰을 두 가지 변형과 비교하여 윤곽 생성에 대한 절제 연구를 수행합니다: (1) 질문 생성 프롬프트에서 관점별을 생략하는 "STORM w/o 관점"; (2) LLM이 모두 설정된 수의 질문을 생성하도록 유도하는 "STORM w/o 대화". 공정한 비교를 위해 모든 변형에서 동일한 총 생성된 질문 수를 제어합니다. 표 3은 절제 결과를 보여주고 전체 스톰 파이프라인은 가장 높은 리콜로 윤곽을 생성합니다. 또한 "스톰 w/o 대화"는 훨씬 더 나쁜 결과를 제공하므로 관련 정보를 tion으로 읽는 것이 효과적인 질문을 생성하는 데 매우 중요하다는 것을 나타냅니다. 우리는 다양한 변형을 통해 R에서 얼마나 많은 고유한 소스가 공동 분류되는지 추가로 조사합니다. 표 5에 나와 있듯이 전체 파이프라인은 더 다양한 소스를 발견하고 추세는 윤곽 품질에 대한 자동 매틱 메트릭과 일치합니다.
또한 스톰을 사용하여 개요 단계가 필요한지 여부도 확인합니다. 표 2에서 "스톰 w/o 개요 단계"는 주제와 시뮬레이션된 대화가 주어진 전체 기사를 생성한 결과를 나타냅니다. 개요 단계를 제거하면 모든 지표에서 성능이 크게 저하됩니다.
[6. Human Evaluation]
스톰의 강점과 약점을 더 잘 이해하기 위해 위키백과에서 최소 500개 이상의 편집을 수행하고 1년 이상의 경력을 가진 숙련된 위키백과 편집자 10명과 협력하여 인간 평가를 실시합니다. 우리는 데이터 세트에서 20개의 주제를 무작위로 샘플링하고 자동 평가에 따라 최적의 기준인 방법과 ORAG로 생성된 기사를 평가합니다. 각 기사 쌍은 2명의 편집자에게 할당됩니다.
편집자는 § 4.2에 정의된 동일한 다섯 가지 측면에서 각 기사를 판단하되, 보다 세분화된 평가를 위해 1~7 척도를 사용할 것을 요청합니다. 자동 평가는 인용 품질을 프록시로 사용하여 검증 가능성을 평가하지만, 인간 평가에서 "원본 연구 없이 검증 가능"이라는 위키피디아 표준을 고수합니다. 편집자는 기사에 대한 평가 외에도 개방형 피드백과 쌍별 선호도를 제공해야 합니다. 평가가 끝나면 방금 검토한 당사의 방법으로 생성된 기사를 인간이 작성한 기사와 비교하고 1-5 리커트 척도를 사용하여 스톰의 인지된 유용성을 보고하도록 요청합니다. 더 많은 인간 평가 세부 정보는 부록 D에 포함되어 있습니다. 표 6은 등급 및 쌍별 비교 결과를 제시합니다.

표 6: STROW와 ORAG에서 생성한 20쌍의 기사에 대한 인간 평가 결과. 각 기사 쌍은 두 명의 위키피디아 편집자가 평가합니다. 평점은 1에서 7 사이의 척도로 제공되며, ≥ 4는 좋은 품질을 나타냅니다(표 10 참조). 페어링된 t-테스트를 수행하여 p-값을 보고합니다.
STOM에서 제작한 기사는 ORAG 출력보다 더 넓은 폭과 깊이를 보여줍니다. § 5.1의 결과에 따라 편집자들은 STOM에서 제작한 기사가 ORAG 출력에 비해 더 흥미롭고 정리되어 있으며 커버리지가 더 넓은 것으로 판단합니다. 특히, STOM에서 제작한 기사는 25% 더 조직적인 것으로 간주되며(조직 등급 ≥ 4), 커버리지가 좋은 것으로 간주되는 기사는 10% 더 많습니다(범위 등급 ≥ 4). 한 편집자는 사람이 작성한 기사와 비교했을 때도 "조금 더 많은 배경 정보"를 제공한 것으로 칭찬하고, 다른 편집자는 "위키피디아 기사에 비해 AI 기사의 깊이가 더 깊다는 것을 발견했다"고 언급합니다. 또한 STORM은 쌍대 비교에서 가장 우수한 기준을 초과 달성했습니다.

그림 3: 스톰의 유용성 인식에 대한 설문조사 결과(n = 10).
|R|의 더 많은 정보는 사실 환각 이상의 문제를 제기합니다. 편집자가 스톰보다 oRAG 출력을 선호하는 14개의 쌍별 비교 응답을 조사합니다. 쌍별 선호도가 등급과 일치하지 않는 3가지 경우를 제외하고, 편집자는 50% 이상의 경우에서 접근 방식의 기사에 낮은 검증 가능성 점수를 부여합니다. 기사와 편집자의 자유 양식 피드백을 분석하여 낮은 검증 가능성 점수가 레드 청어 오류 또는 과잉 추측 문제에서 비롯된 것임을 발견했습니다. 이러한 문제는 생성된 기사가 |R|의 서로 다른 정보 조각 간 또는 정보와 주제 간(예: 표 11에 포함됨)에 검증할 수 없는 연결을 도입할 때 발생합니다. 널리 논의되는 사실 환각(Shuster et al., 2021; Huang et al., 2023)에 비해 이러한 검증 가능성 문제를 해결하는 것은 기본 사실 확인(Min et al., 2023)을 능가하는 미묘한 차이를 보입니다.
생성된 기사는 잘 수정된 인간 작품보다 뒤처집니다. STROW는 ORAG 기준선을 능가하지만, 편집자들은 생성된 기사가 실제 위키피디아 페이지보다 정보가 적다고 말합니다. 확인된 또 다른 주요 문제는 인터넷 출처에서 생성된 기사로 편향성과 톤이 이동하는 것으로, 편집자 10명 중 7명이 STROW 생성 기사가 "정서적" 또는 "비중립적"으로 들린다고 언급했습니다. 자세한 분석은 부록 E에서 논의됩니다. 이 피드백은 사전 작성 단계에서 검색 편향성을 줄이는 것이 향후 작업에 대한 가치 있는 방향임을 시사합니다.
생성된 기사는 좋은 출발점입니다. 그림 3에서 볼 수 있듯이 편집자들은 스톰이 사전 작성 단계에서 도움을 줄 수 있다는 데 만장일치로 동의합니다. 이 도구가 숙련된 편집자에게 도움이 된다는 사실에 만족합니다. 편집자의 80%는 스톰이 새로운 주제에 대한 위키백과 기사를 편집하는 데 도움이 될 수 있다고 생각합니다. 위키백과 커뮤니티 전반에 대한 스톰의 유용성에 대해 더 많은 의구심을 표하지만, 편집자의 70%만이 유용하다고 생각하며 10%만이 동의하지 않습니다.
[7. Related Works]
검색 증강 생성(RAG)
추론 시점에 검색을 통해 언어 모델(LM)을 8월에 멘팅하는 것은 외부 지식 저장소를 활용하는 일반적인 방법입니다(Ram et al., 2023; Izacard et al., 2023). 일부 작업은 검색을 사용하여 컨텍스트 내 학습을 위한 데모를 구성하지만(Li et al., 2023; Liu et al., 2022; Agrawal et al., 2023; Poesia et al., 2022; Shi et al., 2022; Khattab et al., 2022), 또 다른 작업 라인은 검색을 사용하여 LM이 기초가 될 수 있는 추가 정보를 제공합니다. Lewis et al. (2020)은 지식 집약적인 NLP 작업에 대한 RAG를 연구하여 다양성과 사실성을 개선한다는 사실을 발견했습니다. Semnani et al. (2023)은 영어 위키백과에 기반한 RAG 기반 챗봇이 반추되는 것을 막기 위해 서명을 취소합니다. 또한 RAG는 인용문이 포함된 텍스트를 생성하고(Menick et al., 2022; Gao et al., 2023) 귀속 질문 답변 시스템을 구축하는 데 사용할 수 있습니다(Bohnet et al., 2023). RAG는 질문 답변에서 널리 연구되는 반면, 장기 형식의 기사 생성에 이를 사용하는 방법은 덜 조사됩니다.
일반적으로 RAG는 검색 소스와 시간 모두에서 유연합니다. 검색 소스는 도메인 데이터베이스(Zakka et al., 2023), 코드 문서(Zhou et al., 2023), 전체 인터넷(Nakano et al., 2022; Komeili et al., 2022)에 따라 달라질 수 있습니다. 시간과 관련하여, 생성 전에 한 번만 검색하는 것 외에도 시스템은 생성 과정에서 검색 시기를 스스로 결정하도록 설계될 수 있습니다(Jiang et al., 2023b; Parisi et al., 2022; Shuster et al., 2022; Yao et al., 2023).
자동 노출 기록
다른 유형의 장기 형식 생성과 달리(양 등, 2022; 펑 등, 2018) 자동 노출 기록은 외부 문서에 근거하고 읽기와 쓰기 간의 상호 작용을 활용해야 합니다. Balepur 등(2023)은 여러 출처의 정보를 합성하는 데 따르는 어려움을 해결하기 위해 단락 수준의 노출 기록을 위한 모방-검색-가문 프레임워크를 제안합니다. Shen 등(2023)은 출처 요약 외에도 노출 기록 작성을 위해서는 출처 문서와 좋은 개요 계획에 대한 저자의 감각 형성 프로세스가 필요하다는 점을 강조합니다. 우리는 사전 작성 단계에 초점을 맞춰 이러한 과제를 해결합니다.
NLP에서 질문하기
NLP 시스템에서 질문 기능은 사용자 의도를 이해하기 위한 명확한 질문을 생성하고(알리안네자디 외, 2019; 라흐마니 외, 2023), 구성 추론을 개선하기 위해 큰 질문을 작은 질문으로 나누는 등 여러 측면에서 확장되었습니다(Press et al., 2023). 인간은 일반적으로 새로운 지식을 배우기 위해 질문을 하지만(Taw-fik 외, 2020; Booth 외, 2003), 정보를 찾는 대화에서 질문 정보성과 특수성을 최적화하는 방법은 아직 덜 탐구되고 있습니다. 가장 가까운 연구는 i-그램 정밀도 함수를 사용하여 질문 정보성을 정의하고 강화 학습을 사용하여 질문 정보성을 높이는 Qi 외(2020)입니다.
[8. Conclusion]
우리는 위키피디아와 유사한 기사를 처음부터 작성하기 위한 사전 작성 단계를 자동화하는 LLM 기반 작성 시스템인 스톰을 제안합니다. 우리는 FreshWiki 데이터 세트를 큐레이팅하고 평가 기준을 설정하여 근거가 있는 장문형 기사 생성을 연구합니다. 실험 결과에 따르면 스톰의 질문 메커니즘은 개요와 기사 품질을 모두 개선하는 것으로 나타났습니다. 향상된 폭과 깊이를 통해 스톰은 전문가 평가를 통해 근거가 있는 작성 시스템에 대한 새로운 과제를 해결하는 데 도움이 됩니다. 연구의 숙련된 위키피디아 편집자들은 스톰이 사전 작성 단계에 도움이 된다는 데 만장일치로 동의합니다.
[Limitations]
이 연구에서는 자동 노출 작성 및 장기 기사 생성의 최전선을 강화하기 위해 위키피디아와 유사한 기사를 처음부터 생성하는 방법을 모색합니다. 우리의 접근 방식은 자동 평가와 인간 평가 모두에서 기본 방법보다 훨씬 뛰어나지만, 기계로 작성된 기사의 품질은 특히 중립성과 검증 가능성 측면에서 여전히 잘 수정된 인간 저작 기사에 비해 뒤처져 있습니다. 스톰은 주어진 주제를 재검색할 때 서로 다른 관점을 발견하지만, 수집된 정보는 여전히 인터넷의 지배적인 출처에 편향되어 있으며 홍보 콘텐츠를 포함할 수 있습니다. 또한 이 연구에서 확인된 검증 가능성 문제는 사실 환각을 넘어 근거 있는 글쓰기 시스템에 새로운 도전 과제를 강조합니다.
이 작업의 또 다른 한계는 위키피디아와 유사한 글을 처음부터 생성하는 작업에 초점을 맞추고 있지만, 작업 설정이 여전히 자유 형식의 텍스트 생성만 고려하도록 단순화되어 있다는 점입니다. 사람이 직접 작성한 고품질 위키피디아 아티클에는 일반적으로 구조화된 데이터와 다중 모드 정보가 포함되어 있습니다. 향후 작업을 위해 다중 모드 기반 글을 생성하는 탐색은 남겨둡니다.