
[Abstract]
대형 언어 모델은 단계별 시연을 통해 답을 찾도록 안내하는 생각의 사슬 프롬프트를 사용하여 다양한 추론 작업을 수행할 수 있습니다. 그러나 프롬프트의 품질은 모델에 제공된 데모에 따라 달라지며, 많은 프롬프트를 수작업으로 생성하는 데 비용이 많이 듭니다. 우리는 모델이 스스로 더 많은 예제를 생성하도록 유도하기 위해 몇 가지 수작업 예제를 활용하고 더 나은 추론을 이끌어내기 위해 효과적인 시연을 선택하는 방법인 합성 프롬프트를 소개합니다. 우리의 방법은 새로운 예제를 생성하기 위해 역방향 프로세스와 순방향 프로세스를 번갈아 사용합니다. 역방향 프로세스는 샘플링된 추론 체인과 일치하는 질문을 생성하여 질문을 해결할 수 있고 명확하게 합니다. 전진 프로세스는 질문에 대한 보다 상세한 추론 체인을 생성하여 예제의 품질을 향상시킵니다. 우리는 수치, 상징 및 알고리즘 추론 작업에 대한 우리의 방법을 평가하고 그것이 기존의 프롬프트 기술을 능가한다는 것을 보여줍니다.
[Introduction]
작업에 대한 입력 및 출력의 예와 같은 퓨샷 데모를 통해 LLM(Large Language Model)이 미세 조정 없이 다양한 작업을 수행할 수 있습니다(Brown et al., 2020; Chung et al., 2022). LLM은 작업에 대한 중간 추론 단계를 제공하는 사고 체인 프롬프트를 사용하여 성능을 더욱 향상시킬 수 있습니다(Wei et al., 2022b; Kojima et al., 2022). 그러나 LLM의 퓨샷 성능은 특히 복잡하고 다양한 추론 패턴이 필요한 추론 작업의 경우 시연의 품질에 크게 좌우됩니다. 데모 선택을 위해 크고 다양한 예제 세트를 수동으로 만드는 것은 비용이 많이 들고 지루하지만, 제한된 데모 세트에 의존하는 것은 LLM의 일반화와 다양한 테스트 입력에 대한 적응을 방해할 수 있습니다.
본 논문에서는 LLM 자체의 지식과 생성력을 활용하여 제한된 데모 세트를 자체 합성 예제로 보강한 다음 증강 세트를 사용하여 LLM에서 더 나은 추론을 도출하는 새로운 방법인 합성 프롬프트를 제안합니다. 구체적으로, 각각 질문과 일련의 추론 단계로 구성된 몇 가지 시드 예제가 주어지면, 우리는 LLM이 (1) 자체 생성된 추론 체인을 기반으로 질문을 합성하는 역방향 프로세스, 즉, LLM이 자체 생성된 추론 체인을 기반으로 질문을 합성하는 역방향 프로세스입니다, 이는 질문에 답할 수 있고 잘 정의되어 있음을 보장합니다. 그리고 (2) LLM이 합성된 질문에 대한 추론 체인을 생성하는 전진 프로세스로, 추론 체인이 질문과 더 정확하고 일치하도록 정제합니다. 우리는 충분한 합성 예제를 얻을 때까지 이 과정을 반복합니다. 증강 세트에서 가장 효과적인 데모를 선택하기 위해, 우리는 클러스터 내 복잡성을 기반으로 하는 새로운 선택 체계를 제안합니다. 이는 데모를 클러스터링하고 각 클러스터에서 가장 복잡한 것(추론 체인이 가장 긴 것)을 선택하여 데모의 다양성과 정보성을 극대화하는 것을 목표로 합니다. 마지막으로, 우리는 선택된 시연으로 LLM에 요청하여 테스트 질문에 대한 추론 체인을 생성한 다음 이를 사용하여 답을 얻습니다.
우리는 수치 추론, 알고리즘 추론 및 기호 추론을 포함한 다양한 추론 작업에 대한 우리의 방법을 평가합니다. 이전의 퓨샷 설정(Wang et al., 2022b; Suzgun et al., 2022)에 따라, 우리의 방법이 최첨단 방법에 비해 최대 15.6%의 절대적인 이득을 달성하면서 LLM의 성능을 크게 향상시킬 수 있음을 보여줍니다.
우리의 주요 기여는 :
우리는 LLM을 요청하여 제한된 데모 세트를 자체 합성된 예제로 보강하고, 증강 세트를 활용하여 LLM에서 더 나은 추론을 도출하는 새로운 방법인 합성 프롬프트를 소개합니다.
우리는 추론을 위해 증강 세트에서 다양하고 유익한 시연을 선택하기 위한 클러스터 내 복잡성 기반 체계를 제안합니다.
우리는 세 가지 추론 작업에 대한 우리 방법의 효과를 입증하여 이전 방법보다 크게 개선되었습니다.
[Related work]
상황별 퓨샷 학습
대규모 비지도 사전 훈련을 통해 LLM(Brown et al., 2020; Chowdhery et al., 2022; Zhang et al., 2022a)은 문맥 내 시연을 모방하여 작업을 수행하는 방법을 배울 수 있습니다(Shin et al., 2022a). 프롬프트에 대한 견고성을 개선하기 위해 다양한 작업에 대해 언어 모델을 훈련하여 주어진 명령을 따르는 바람직한 출력을 생성하는 명령 튜닝(Ouyang et al., 2022; Wei et al., 2022a; Sanh et al., 2022; Chung et al., 2022)이 제안되었습니다. 제어 가능성이 향상됨에 따라 텍스트 생성(Yang et al., 2022; Gao et al., 2022a), 대화 생성(Thopilan et al., 2022), 자원 구축(West et al., 2022) 등 컨텍스트 학습 기반 애플리케이션이 번창하고 있습니다.
추론을 위한 기술을 유도
직접적으로 답변을 생성하는 대신, 생각의 사슬 프롬프트(Wei et al., 2022b)는 LLM이 단계별 추론 프로세스 후에 답변에 도달하도록 유도하며, 이는 수많은 추론 작업에 대한 성능을 크게 향상시킵니다. 가장 덜 재촉하는 것(Zhou et al., 2022), 셀프 질문(Press et al., 2022), 분해된 요청(Khot et al., 2022)과 같은 작업에 이어 복잡한 질문을 일련의 다루기 쉬운 하위 질문으로 분해하는 질문 분해 정신도 공유합니다. 이 모든 방법은 계산과 기호 조작으로 어려움을 겪는 자연어 추론 단계를 생성합니다. PAL 프롬프트(Gao et al., 2022b) 및 생각의 프로그램 프롬프트(Chen et al., 2022)와 같은 기술은 구조화된 코드로 자연어 추론을 개선하여 산술, 상징 및 알고리듬 작업에서 상당한 개선을 보여줄 것을 제안합니다.
프롬프트 워크플로우와 직교하여 효과적인 데모를 만드는 방법을 탐구하는 작업도 있습니다. 메트릭에는 (1) 모델이 서로 다른 추론(Li et al., 2022; Ye et al., 2022b)을 융합하거나 한 가지 유형의 추론(Zhang et al., 2022b)에 의해 덜 편향될 수 있도록 보완적인 시연을 선택하는 다양성; (2) 추론 복잡성이 가장 높은 시연을 선택합니다, 그리고 경험적으로 수치 추론(Fu et al., 2022), (3) 구조적으로(Drozdov et al., 2022) 또는 의미적으로(Liu et al., 2022b) 유사한 시연을 검색하는 테스트 입력과의 유사성에서 잘 작동하는 것으로 밝혀졌습니다.
데모의 다양성과 정보성을 모두 보장하기 위해 예제 클러스터에서 가장 복잡한 예제를 선택하는 클러스터 내 복잡성에 기반한 선택 체계를 제안합니다. 이러한 모든 선택 체계는 (주석이 있든 없든) 일련의 예제에 대한 액세스를 가정합니다.
LLM을 통한 지식 증류
일부 연구에서는 LLM의 지식을 상징적 지식(예: 구조화된 상식 지식(West et al., 2022) 또는 작업별 예(Liu et al., 2022a; Ye et al., 2022a; Huang et al., 2022)로 증류했습니다. 이러한 연구는 (1) 교육 세트에서 금 입력을 생성할 필요 없이 금 입력에 액세스할 수 있다고 가정하고, (2) 작업자와 AI 간의 협업을 기반으로 지식을 증류하고, (3) 교육을 위해 증류된 지식을 사용하는 특성 중 하나 이상을 가지고 있습니다.
대조적으로, 우리는 몇 가지 골드 예제에만 액세스한다고 가정하고, LLM을 요청하여 더 많은 예제를 자동으로 합성하고, 합성된 예제를 추가 훈련 없이 모델 자체에서 추론을 더 잘 도출할 수 있는지 여부를 연구합니다.
[3. Synthetic Prompting]
[3.1 overview]
각각 질문과 추론 체인으로 구성된 몇 가지 예를 고려할 때 LLM으로 추론 작업을 수행하려면 추론을 위한 프롬프트로 직접 연결하는 것이 일반적입니다. 이 논문에서, 우리는 대신 그것들을 시드 예제로 취급하고, LLM이 역방향 절차를 반복하여 자동으로 더 많이 합성하도록 촉구합니다. 역방향 프로세스와 순방향 프로세스는 각각 질문과 해당 추론 체인을 생성합니다. 추론 중에 LLM은 모델 자체에서 추론을 더 잘 이끌어내기 위해 자체 합성 시연으로 유도됩니다. 데모는 다양성과 정보 제공을 보장하는 새로운 계획으로 선택됩니다.
[3.2 Example Synthesis Phase]
시드 데모를 사용하여 역방향 프로세스를 반복하여 더 많은 예제를 자동으로 합성합니다.
각 합성 예제는 { 질문, 추론 체인 } 쌍입니다. 우리의 주요 실험에서, 우리는 PAL 스타일 추론을 사용합니다. 즉, 추론 체인은 코드의 일부이며, 코드를 실행하여 답을 얻습니다.
[3.2.1 Backward Process]
역방향 프로세스에서 LLM은 먼저 추론 체인을 생성한 다음 질문을 생성하라는 메시지를 받습니다. 역방향 프로세스의 출력인 질문은 주어진 주제 단어, 목표 추론 복잡성 및 자체 생성 추론 체인을 기반으로 합성됩니다. 그림 1(왼쪽)은 하위 프로세스에 대한 예제 프롬프트를 보여줍니다. 여기에는 시드 예제와 이전에 합성된 예제에서 무작위로 샘플링된 일부 데모가 포함됩니다. 시연의 수는 시드 예제의 수와 같습니다.

주제어
우리는 각 추론 질문이 특정 주제와 관련되어 있으며, 주제마다 다른 유형의 추론이 필요할 수 있다고 가정합니다. 예를 들어, 세금에 관한 질문은 산술 연산을 포함하는 반면, 속도에 관한 질문은 단위 변환을 포함할 수 있습니다.
합성된 질문의 다양성을 보장하기 위해, 우리는 모델이 주어진 주제 단어에 대한 질문을 생성하도록 촉구하며, 이는 단어 집합에서 무작위로 샘플링됩니다. 단어 집합은 모델이 시드 예제의 일부 임의 명사 단어를 따라 단일 토큰 명사 단어를 나열하도록 요청하여 생성됩니다. 단어 집합을 생성하는 방법은 명사 단어 50개 나열입니다. 각 단어에는 토큰이 하나만 포함되어야 합니다. 시드 예제에서 10개 이하의 단어 뒤에 이미 나열된 단어를 반복하지 마십시오. 우리는 1,000개의 다른 단어가 있거나 100번의 반복적인 프롬프트에 도달할 때까지 이 과정을 반복합니다.
대상 복잡도
우리는 또한 더 복잡한 예들이 모델이 더 나은 추론 기술을 배우는 데 도움이 될 수 있기 때문에 합성된 질문의 복잡성을 제어하고 싶습니다(Fu et al., 2022). 우리는 질문의 복잡성을 질문에 답하는 데 필요한 추론 단계의 수로 정의합니다. 여기서 단계는 줄 바꿈으로 구분된 코드 줄입니다. 예를 들어 그림 1(왼쪽)의 예제 1은 5줄의 코드를 가지고 있기 때문에 복잡도가 5입니다. 질문을 생성하기 위한 목표 복잡도는 시드 예제의 가장 낮은 복잡도에서 가장 높은 1 더하기 c까지의 범위에서 무작위로 샘플링됩니다.
자체 생성 추론 체인
우리는 모델이 주어진 주제에 대한 목표 복잡성의 추론 체인을 생성한 다음 추론 체인을 기반으로 질문을 생성하도록 촉구합니다. 우리는 이 접근 방식이 추론 체인 없이 직접 질문을 생성하는 것에 비해 더 대답 가능하고 잘 정의된 질문으로 이어진다는 것을 발견했습니다. 모델이 목표 복잡성을 따르도록 유도하기 위해 시연의 각 추론 단계(예: 그림 1(왼쪽)의 #1 및 #2)에 번호를 매깁니다. 중복된 질문을 걸러내거나, 5-그램 이상 반복하거나, 주어진 주제어를 언급하지 않습니다.
[3.2.2 Forward Process]
전진 과정은 후진 과정에서 합성된 질문에 대한 추론 체인을 생성하는 것을 목표로 합니다. 그림 1(오른쪽)은 시드 예제로 구성된 전달 프로세스에 대한 예제 프롬프트를 보여줍니다. PAL 프롬프트는 모델 출력에서 추출하는 것이 아니라 생성된 코드를 실행하여 응답을 얻을 수 있기 때문에 일련의 질문 프롬프트와 달리 최종 답변을 프롬프트에 포함하지 않습니다. 우리는 전방 프로세스에서 생성된 추론 체인이 후방 프로세스에서 생성된 것보다 더 관련성이 있고 정확하다는 것을 관찰합니다. 왜냐하면 그것은 질문에 직접적으로 조건화되기 때문입니다.
우리는 또한 모델이 추론 체인에 의해 생성된 답에 대해 확신을 가질 수 있도록 하고 싶습니다. Huang et al.(2022)에 이어 동일한 답변으로 이어지는 샘플링된 추론 체인의 비율로 답변의 신뢰도를 측정합니다. 질문 x의 경우, 우리는 m개의 추론 체인을 샘플링하고 그들의 답 {a1, a2, ...am}을 얻습니다.
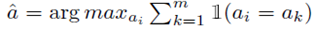
m/2 이상의 추론 체인이 ^a로 이어지는 경우, 우리는 가장 짧은 것을 합성된 질문과 연결합니다. 그렇지 않으면 모델이 이에 대한 확신 있는 추론 체인을 생성하지 못하기 때문에 질문을 폐기합니다. 다수결 투표는 추론이 아닌 예제 합성에만 사용됩니다(섹션 3.3). 이는 다수결을 추론에 사용하는 Wang 등(2022a)과는 다릅니다.
[3.3 Inference Phase] 추론 단계
추론하는 동안, 우리는 모델에 대한 시연으로 합성된 예제의 하위 집합을 선택합니다. Fu et al. (2022)에 따르면, 복잡성을 기반으로 데모를 선택하면 유사성을 기반으로 모델을 선택하는 것에 비해 추론 작업에 대한 모델의 성능을 향상시킬 수 있습니다. 또한 유사성을 기반으로 데모를 선택하면 데모에서 편견(장 외, 2022b; 류 외, 2022)이 발생할 수 있습니다. 특히 잘못된 경우에는 더욱 그렇습니다. 또한 서로 보완적인 데모를 선택하면 모델이 다양한 유형의 추론 지식을 융합하는 데 도움이 될 수 있습니다(Ye et al., 2022b; Zhang et al., 2022b).
따라서 복잡하고 보완적인 데모를 선택하기 위한 클러스터 내 복잡성 기반 체계를 제안합니다. 구체적으로, 우리는 합성된 예제를 시맨틱 임베딩 공간에 클러스터링하고, SentenceBERT(Reimers & Gurevych, 2019)를 인코더로 사용합니다. 군집의 수는 추론에 사용되는 시연의 수와 같습니다. 그런 다음 각 클러스터에서 가장 복잡한 예제를 시연으로 선택합니다. 추론 프로세스는 모델이 주어진 프롬프트를 완료하는 PAL 프롬프트와 같은 이전 작업과 동일합니다. 유일한 차이점은 프롬프트의 데모가 시드 예제에 고정되지 않고 시드 예제에서 합성된다는 것입니다.
[4. Experiments]
[4.1 Datasets]
우리는 서로 다른 추론 작업의 7개 데이터 세트에 대해 실험했습니다. 예는 표 1에 제시되어 있습니다.
수치추론
(1) GSM8K (Cobbe et al., 2021)는 1,319개의 다양한 초등학교 수학 단어 문제의 데이터 세트로, LLM의 다단계 수학 추론 능력을 평가하기 위해 큐레이션되었습니다. (2) GSM-Hard는 가오 et al. (2022b)이 문제의 숫자를 더 큰 숫자로 대체하여 만든 GSM8K의 더 단단한 버전입니다, LLM이 큰 숫자로 일반화할 수 있는지 여부를 평가하기 위한 것입니다. (3) SVAMP(Patel et al., 2021)는 견고성 평가를 위한 1,000개의 질문이 있는 수학 단어 문제 데이터 세트입니다. (4) ASDiv(Miao et al., 2020)는 2,000개의 다양한 수학 단어 문제로 구성됩니다. (5) SingleOp(Koncel-Kedziorski et al., 2016)는 562개의 수학 단어 문제로 구성됩니다.
상징적 추론
BigBench Hard(Suzgun et al., 2022)의 Colored Objects 과제는 주어진 물체의 위치와 색상 속성에 대한 2,000개의 질문을 포함합니다.
알고리즘 추론
반복 복사 작업은 또한 32개의 테스트 예제로 구성된 Big-Bench Hard에서 제공됩니다. 모델은 주어진 명령어의 요구 사항을 충족하는 일련의 단어를 생성해야 합니다.
[4.2 Evaluation Settings]
Suzgun 외 연구진(2022)과 Wang 외 연구진(2022b) 모두 4개 이하의 골드 예제에 액세스할 수 있는 퓨샷 설정에서 수많은 작업을 통해 벤치마크에서 LLM을 평가했습니다.
이러한 설정에 따라 기본적으로 각 데이터 세트에서 2개 또는 4개의 랜덤 예제에 액세스할 수 있다고 가정했습니다. 수치 추론 과제의 경우, Wei et al. (2022b)가 수작업으로 제작하고 여러 논문에 의해 채택된 8가지 예를 실험했습니다(Fu et al., 2022a; Gao et al., 2022b). 우리는 또한 Gao et al. (2022b)가 주석을 단 PAL 스타일 추론 체인을 사용했습니다.

합성 없이 기준선을 유도하는 것은 제공된 모든 금 예제를 사용하여 추론을 위한 프롬프트를 구성합니다. 합성 프롬프트 및 그 변형은 제공된 예제를 사용하여 예제를 합성하고, 달리 명시되지 않는 한 클러스터 내 복잡성을 기준으로 8개의 합성 시연을 선택합니다.
시드 예제 및 합성 프롬프트는 보충 자료에 나와 있습니다.
[4.3 Baselines]
직접 확인
직접 프롬프트(Brown et al., 2020)는 LLM이 입력-응답 쌍 시연을 통해 답변을 직접 생성하도록 요청합니다.
CoT 프롬프트 표시
사고 체인 프롬프트(Wei et al., 2022b)는 LLM에서 추론을 도출하는 데 효과적이며, 이는 LLM이 자연어 추론 단계를 생성한 후 답변을 생성하도록 촉구합니다.
PAL 프롬프트 표시
PAL 프롬프트(Gao et al., 2022b)는 사고 체인 프롬프트의 변형으로 구조화된 코드로 추론을 개선합니다. 그림 1(오른쪽)은 두 가지 예를 제공합니다. LLM은 최종 답변을 완료에 포함하도록 요청하지 않습니다. 답변은 코드를 실행하여 얻을 수 있습니다. 이 촉진 기술은 수많은 추론 작업에서 최첨단 결과를 달성했습니다.
바닐라 합성 프롬프트
이는 질문 합성에 사용되는 프롬프트가 시드 예제의 질문으로만 구성된다는 점에서 다른 합성 프롬프트의 변형입니다. 즉, 새로운 질문은 다른 조건 없이 시드 질문을 모방하여 합성됩니다.
[4.4 Implementation Details]
우리는 자연어 추론 단계인 주석을 가진 구조화된 코드인 PAL 스타일 추론 체인을 채택했습니다.
Text-davinci-003 버전의 Instruct GPT(Ouyang et al., 2022)는 합성과 추론 모두를 위해 백엔드 LLM로 사용되었습니다. 온도가 0.7로 설정된 합성에 top-p 샘플링(Holtzman et al., 2020)을 사용했고, 온도가 0으로 설정된 추론에 탐욕스러운 디코딩을 사용했습니다. 모든 수치 추론 데이터 세트는 GSM8K(시드 수가 2 또는 4일 때) 또는 Wei et al.(2022b)(시드 수가 8일 때)에서 무작위로 샘플링된 시드 예제 세트를 공유합니다. 다른 작업의 데이터 세트의 경우, 시드는 자체 데이터 세트에서 무작위로 샘플링되었습니다.
우리는 주석 프로토콜에 따라 CoT 스타일 추론 체인과 PAL 스타일 추론 체인을 모두 수동으로 사용하여 시드 예제에 주석을 달았습니다. 주석은 보충 자료에 나와 있습니다. 각 시드 예제 세트에 대해 1,000회 역방향 합성을 반복하여 더 많은 예제를 합성했습니다. 대상 복잡도는 시드 예제의 가장 낮은 복잡도에서 가장 높은 복잡도 c에 이르기까지 다양합니다. c는 수치 추론을 위해 4로, 다른 데이터 세트에서는 2로 설정되었습니다. 전방 합성에서 각 질문에 대해 샘플링된 추론 체인의 수는 3개였습니다. 클러스터링에 사용된 인코더는 all-mpnet-base-v2였습니다.
[4.5 Main Result]
표 2에 나타난 바와 같이, 합성 프롬프트는 PAL 프롬프트를 최대 15.6%까지 지속적으로 능가하며, 이는 자체 합성 데모를 활용하여 LLM 자체에서 추론을 더 잘 도출할 수 있으며, 시드 데모만 사용하는 성능을 능가할 수 있음을 나타냅니다.
바닐라 합성 프롬프트도 합성 데모를 사용하지만 PAL 프롬프트보다 일관되게 개선되지 않습니다. 복잡한 추론이 필요한 질문을 포함하는 GSM8K 및 GSM-Hard에서 바닐라 합성 프롬프트는 합성 예제의 추론 복잡성을 명시적으로 제어하지 않고 복잡성과 정보성 측면에서 시드 예제와 유사한 예제를 합성하는 경향이 있기 때문에 PAL 프롬프트보다 거의 개선되지 않습니다. 특히 바닐라 합성 프롬프트는 2개의 시드 예제를 사용하여 Repeat Copy에서 PAL 프롬프트를 크게 능가합니다. 선택된 두 개의 데모에 잘못된 형식의 질문이 있음을 발견했습니다(예: " 문장 반복")태양은 밝다"는 말을 다섯 번 할 때마다 다르게 강조합니다. 이는 질문이 추론 체인에 대한 명확한 인식 없이 합성되기 때문일 수 있습니다. 섹션 4.6.1은 다양한 조건으로 질문 합성을 제어하는 이점을 보여줍니다.

또한 시드 예제의 수를 2개에서 8개로 늘린다고 해서 성능이 크게 향상되지는 않는다는 것을 알 수 있습니다. 특히 GSM8K 및 Repeat Copy에서 그렇습니다. 두 가지 가능한 이유는 다음과 같습니다. (1) 합성 예제는 시드 예제에 의해 편향됩니다. 제한된 시드를 사용하면 합성된 예제가 충분히 다양하지 않고 테스트 질문의 일부에서 여전히 무력할 수 있습니다. (2) 제안된 시연 선택 체계는 효과적이지만(섹션 4.6.2의 분석 참조) 합성된 예제를 최대한 활용하지 못해 차선일 수 있습니다.
[4.6 Ablation Studies] -> 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하고 싶을 때 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말한다!!!!!!!@
우리는 주로 GSM8K와 Colored Objects 작업에 대한 절제 연구를 수행했습니다.
4.6.1. CONDITIONS USED FOR QUESTION SYNTHESIS

역방향 합성에서, 우리는 LLM에게 주제, 대상 복잡성 및 샘플링된 추론 체인에 대해 조건부 질문을 샘플링할 것을 요청합니다. 질문 합성에 대한 각 조건의 영향을 분석하기 위해 프롬프트에서 해당하는 줄을 제거했습니다. 특히, 대상 복잡성을 제거할 때 추론 단계의 숫자 마커도 제거됩니다. 표 3에서 볼 수 있듯이, 어떤 조건이라도 제거하면 GSM8K와 유색 물체 모두에서 모델 성능이 저하됩니다.

우리는 또한 (1) 평균적으로 합성 예와 다른 예 사이의 최대 쌍별 코사인 유사성으로 측정되는 다양성, (2) 복잡성, 평균 추론 단계 수, (3) 정확성 측면에서 서로 다른 조건이 합성 예의 품질에 어떻게 영향을 미치는지 조사했습니다, 정확한 추론에 사용되는 시연 부분으로 측정됩니다. 표 4는 GSM8K에 대한 분석을 보여줍니다. 주제 단어를 제거하면 합성 예제의 종류가 줄어듭니다. 선택된 데모의 추론 패턴도 제한적입니다. 모든 데모가 정확하지만 62.5%의 질문이 할인 또는 세금과 관련이 있습니다. 대상 복잡성을 제거하면 훨씬 더 간단한 합성 예제가 생성됩니다. 추론 체인에 조건 없이 질문을 종합하는 것은 정확성에 부정적인 영향을 미칩니다. 62.5%는 결함이 있으며, 그 중 80%는 답할 수 없습니다. 예를 들어,
이미지는 4x4 정수 행렬로 표시됩니다. 행렬의 각 셀에는 0과 255 사이의 단일 정수가 포함됩니다. 행렬의 모든 정수의 평균 값은 얼마입니까?
특히, 추론 체인에 조건 없이 질문을 합성할 때 프롬프트에 대상 복잡성도 포함하지만, 결과 질문은 합성 프롬프트보다 추론 단계를 덜 필요로 하는 경향이 있으며, 이는 번호가 매겨진 추론 단계를 조건화하면 추론 복잡성을 더 잘 제어할 수 있음을 나타냅니다.
[4.6.2 Schemes of Demonstration Selection]

합성된 예제를 잘 활용하려면 효과적인 선택 체계가 중요합니다. 우리는 다음 6가지 선택 체계를 평가했습니다. (1) 무작위: 시연을 무작위로 선택; (2) 군집 중심: 각 군집 중심에 가장 가까운 예제를 선택; (3) 유사성: 코사인 유사성에 따라 가장 유사한 예제를 검색; (4) 군집 내 유사성: 각 군집에서 가장 유사한 예제를 선택; (5) 복잡성: 가장 추론이 많은 예제를 선택합니다 단계; (6) 클러스터 내 복잡성: 각 클러스터에서 가장 복잡한 예제를 선택합니다.
표 5는 비교를 보여줍니다. 대부분의 선택 체계가 PAL 프롬프트보다 더 나은 성능을 달성하지만, 복잡성 기반 선택 체계는 무작위와 같은 일부 다른 체계가 훨씬 뒤떨어져 두 가지 추론 작업에 가장 효과적입니다. 제안된 클러스터 내 복잡성은 복잡성을 능가하여 다양하고 복잡한 데모를 사용하는 이점을 보여줍니다.
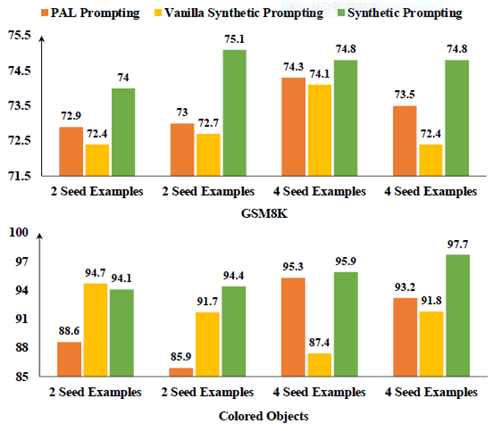
[4.6.3 Sensitivity to Seed Examples]
합성 프롬프트가 예제를 시드하는 데 얼마나 민감한지 조사하기 위해, 우리는 또 다른 두 개의 무작위 시드 세트에 대한 실험을 반복했습니다. 그림 2는 민감도 분석을 보여줍니다. 합성 프롬프트는 여러 실행에서 지속적으로 PAL 프롬프트를 능가합니다. 그러나 PAL 프롬프트 성능이 향상된 시드 예제가 반드시 합성 프롬프트 성능이 향상되는 것은 아니라는 것을 관찰했습니다.
[4.7 Comparison with selecting from training Examples]
합성 시연을 사용하는 것과 신중하게 선별된 대규모 예제에서 금 시연을 사용하는 것 사이의 성능 차이를 측정하기 위해, 우리는 GSM8K의 훈련 세트에서 각각 두 가지 복잡성 기반 선택 체계(즉, 섹션 4.6.2의 복잡성 및 클러스터 내 복잡성)와 함께 8개의 시연을 선택했습니다. 훈련 예제가 자연어 추론 체인(CoT 스타일 추론)으로 주석을 달았기 때문에, 우리는 복잡성 기반 선택을 위한 추론 복잡성으로 자연어 추론 단계의 수를 측정했고, PAL 프롬프트를 위한 PAL 스타일 추론 체인을 사용하여 선택된 예제에 수동으로 주석을 달았습니다. GSM8K의 교육 사례는 다양하기 때문에 복잡성과 클러스터 내 복잡성 모두 다양하고 유익한 시연을 선택하며 GSM8K의 테스트 세트에서 77.0%의 정확도를 보여주며 당사의 정확도인 75.3%를 절대 1.7%로 능가합니다. 보충 자료에 나와 있는 것처럼, 합성 시연과 비교하여, 선택된 금 시연은 논리적으로 더 복잡하고 덜 간단한 추론으로 LLM에 더 많은 정보를 줄 수 있습니다.
특히, 신속한 엔지니어링 없이 수동으로 제작된 Wei et al. (2022b)의 8개의 간단한 시연을 사용하면 정확도가 71.8%로 훨씬 낮아집니다. 이것은 시위가 실제로 중요하다는 것을 나타냅니다. 제한적이고 아마도 단순한 예제에만 액세스할 수 있는 시나리오에서, 더 효과적인 데모를 선택하기 위한 예제를 자동으로 합성하는 것은 LLM에서 더 나은 추론을 이끌어낼 수 있는 유망한 방법입니다.

[4.8 Quality Analysis of Synthetic Examples]
합성된 예제의 품질을 조사하기 위해 GSM8K에 대한 수동 평가를 수행했습니다. 합성 프롬프트와 바닐라 합성 프롬프트로 합성된 25개의 무작위 예를 각각 평가했습니다. 바닐라 합성 프롬프트와 비교하여 합성 프롬프트는 더 높은 복잡도(8.3 대 5.4)와 더 낮은 오류율(8% 대 24%)의 질문을 합성합니다.
우리는 선택된 합성 시연의 품질을 추가로 분석합니다.
합성 프롬프트의 경우 선택한 모든 데모가 올바른 반면 바닐라 버전에는 대답할 수 없는 질문과 잘못된 추론이 있는 질문이 있습니다.
표 6은 두 개의 시드 예제와 일부 합성 데모를 보여줍니다. 바닐라 합성 프롬프트의 경우 처음 두 질문은 논리적으로 시드 질문에 가깝고 세 번째 질문은 답할 수 없습니다. 합성 프롬프트를 사용하여 LLM은 새로운 추론 패턴이 필요한 주제의 질문을 합성할 수 있습니다. 예를 들어 사무실에 대한 두 번째 질문에는 기하학적 추론이 필요합니다.
[5. Conclusion]
우리는 몇 가지 예를 사용하여 대규모 언어 모델을 추론하기 위한 새로운 기술인 합성 프롬프트를 소개합니다. 이는 모델을 컨텍스트 내 데모의 소비자뿐만 아니라 추가 예제의 생성기로 사용하여 이전 작업과 다릅니다. 우리는 큰 언어 모델이 더 많은 예를 합성하도록 유도함으로써, 우리가 생각의 사슬 프롬프트 및 PAL 프롬프트와 같은 기존의 프롬프트 방법에 비해 수치, 상징 및 알고리듬 작업에 대한 추론 성능을 향상시킬 수 있음을 보여줍니다.